string — Common string operations¶
Source code: Lib/string.py
String constants¶
The constants defined in this module are:
The concatenation of the ascii_lowercase and ascii_uppercase constants described below. This value is not locale-dependent.
The lowercase letters ‘abcdefghijklmnopqrstuvwxyz’ . This value is not locale-dependent and will not change.
The uppercase letters ‘ABCDEFGHIJKLMNOPQRSTUVWXYZ’ . This value is not locale-dependent and will not change.
The string ‘0123456789abcdefABCDEF’ .
String of ASCII characters which are considered punctuation characters in the C locale: !”#$%&'()*+,-./:; ?@[\]^_`
String of ASCII characters which are considered printable. This is a combination of digits , ascii_letters , punctuation , and whitespace .
A string containing all ASCII characters that are considered whitespace. This includes the characters space, tab, linefeed, return, formfeed, and vertical tab.
Custom String Formatting¶
The built-in string class provides the ability to do complex variable substitutions and value formatting via the format() method described in PEP 3101. The Formatter class in the string module allows you to create and customize your own string formatting behaviors using the same implementation as the built-in format() method.
The Formatter class has the following public methods:
format ( format_string , / , * args , ** kwargs ) В¶
The primary API method. It takes a format string and an arbitrary set of positional and keyword arguments. It is just a wrapper that calls vformat() .
Changed in version 3.7: A format string argument is now positional-only .
This function does the actual work of formatting. It is exposed as a separate function for cases where you want to pass in a predefined dictionary of arguments, rather than unpacking and repacking the dictionary as individual arguments using the *args and **kwargs syntax. vformat() does the work of breaking up the format string into character data and replacement fields. It calls the various methods described below.
In addition, the Formatter defines a number of methods that are intended to be replaced by subclasses:
Loop over the format_string and return an iterable of tuples (literal_text, field_name, format_spec, conversion). This is used by vformat() to break the string into either literal text, or replacement fields.
The values in the tuple conceptually represent a span of literal text followed by a single replacement field. If there is no literal text (which can happen if two replacement fields occur consecutively), then literal_text will be a zero-length string. If there is no replacement field, then the values of field_name, format_spec and conversion will be None .
get_field ( field_name , args , kwargs ) В¶
Given field_name as returned by parse() (see above), convert it to an object to be formatted. Returns a tuple (obj, used_key). The default version takes strings of the form defined in PEP 3101, such as “0[name]” or “label.title”. args and kwargs are as passed in to vformat() . The return value used_key has the same meaning as the key parameter to get_value() .
get_value ( key , args , kwargs ) В¶
Retrieve a given field value. The key argument will be either an integer or a string. If it is an integer, it represents the index of the positional argument in args; if it is a string, then it represents a named argument in kwargs.
The args parameter is set to the list of positional arguments to vformat() , and the kwargs parameter is set to the dictionary of keyword arguments.
For compound field names, these functions are only called for the first component of the field name; subsequent components are handled through normal attribute and indexing operations.
So for example, the field expression вЂ0.name’ would cause get_value() to be called with a key argument of 0. The name attribute will be looked up after get_value() returns by calling the built-in getattr() function.
If the index or keyword refers to an item that does not exist, then an IndexError or KeyError should be raised.
check_unused_args ( used_args , args , kwargs ) В¶
Implement checking for unused arguments if desired. The arguments to this function is the set of all argument keys that were actually referred to in the format string (integers for positional arguments, and strings for named arguments), and a reference to the args and kwargs that was passed to vformat. The set of unused args can be calculated from these parameters. check_unused_args() is assumed to raise an exception if the check fails.
format_field ( value , format_spec ) В¶
format_field() simply calls the global format() built-in. The method is provided so that subclasses can override it.
convert_field ( value , conversion ) В¶
Converts the value (returned by get_field() ) given a conversion type (as in the tuple returned by the parse() method). The default version understands вЂs’ (str), вЂr’ (repr) and вЂa’ (ascii) conversion types.
Format String Syntax¶
The str.format() method and the Formatter class share the same syntax for format strings (although in the case of Formatter , subclasses can define their own format string syntax). The syntax is related to that of formatted string literals , but it is less sophisticated and, in particular, does not support arbitrary expressions.
Format strings contain “replacement fields” surrounded by curly braces <> . Anything that is not contained in braces is considered literal text, which is copied unchanged to the output. If you need to include a brace character in the literal text, it can be escaped by doubling: << and >> .
The grammar for a replacement field is as follows:
In less formal terms, the replacement field can start with a field_name that specifies the object whose value is to be formatted and inserted into the output instead of the replacement field. The field_name is optionally followed by a conversion field, which is preceded by an exclamation point ‘!’ , and a format_spec, which is preceded by a colon ‘:’ . These specify a non-default format for the replacement value.
The field_name itself begins with an arg_name that is either a number or a keyword. If it’s a number, it refers to a positional argument, and if it’s a keyword, it refers to a named keyword argument. If the numerical arg_names in a format string are 0, 1, 2, … in sequence, they can all be omitted (not just some) and the numbers 0, 1, 2, … will be automatically inserted in that order. Because arg_name is not quote-delimited, it is not possible to specify arbitrary dictionary keys (e.g., the strings ’10’ or ‘:-]’ ) within a format string. The arg_name can be followed by any number of index or attribute expressions. An expression of the form ‘.name’ selects the named attribute using getattr() , while an expression of the form ‘[index]’ does an index lookup using __getitem__() .
Changed in version 3.1: The positional argument specifiers can be omitted for str.format() , so ‘<> <>‘.format(a, b) is equivalent to ‘ <0><1>‘.format(a, b) .
Changed in version 3.4: The positional argument specifiers can be omitted for Formatter .
Some simple format string examples:
The conversion field causes a type coercion before formatting. Normally, the job of formatting a value is done by the __format__() method of the value itself. However, in some cases it is desirable to force a type to be formatted as a string, overriding its own definition of formatting. By converting the value to a string before calling __format__() , the normal formatting logic is bypassed.
Three conversion flags are currently supported: ‘!s’ which calls str() on the value, ‘!r’ which calls repr() and ‘!a’ which calls ascii() .
The format_spec field contains a specification of how the value should be presented, including such details as field width, alignment, padding, decimal precision and so on. Each value type can define its own “formatting mini-language” or interpretation of the format_spec.
Most built-in types support a common formatting mini-language, which is described in the next section.
A format_spec field can also include nested replacement fields within it. These nested replacement fields may contain a field name, conversion flag and format specification, but deeper nesting is not allowed. The replacement fields within the format_spec are substituted before the format_spec string is interpreted. This allows the formatting of a value to be dynamically specified.
See the Format examples section for some examples.
Format Specification Mini-Language¶
“Format specifications” are used within replacement fields contained within a format string to define how individual values are presented (see Format String Syntax and Formatted string literals ). They can also be passed directly to the built-in format() function. Each formattable type may define how the format specification is to be interpreted.
Most built-in types implement the following options for format specifications, although some of the formatting options are only supported by the numeric types.
A general convention is that an empty format specification produces the same result as if you had called str() on the value. A non-empty format specification typically modifies the result.
The general form of a standard format specifier is:
If a valid align value is specified, it can be preceded by a fill character that can be any character and defaults to a space if omitted. It is not possible to use a literal curly brace (” < ” or “ >”) as the fill character in a formatted string literal or when using the str.format() method. However, it is possible to insert a curly brace with a nested replacement field. This limitation doesn’t affect the format() function.
The meaning of the various alignment options is as follows:
Forces the field to be left-aligned within the available space (this is the default for most objects).
Forces the field to be right-aligned within the available space (this is the default for numbers).
Forces the padding to be placed after the sign (if any) but before the digits. This is used for printing fields in the form вЂ+000000120’. This alignment option is only valid for numeric types. It becomes the default for numbers when вЂ0’ immediately precedes the field width.
Forces the field to be centered within the available space.
Note that unless a minimum field width is defined, the field width will always be the same size as the data to fill it, so that the alignment option has no meaning in this case.
The sign option is only valid for number types, and can be one of the following:
indicates that a sign should be used for both positive as well as negative numbers.
indicates that a sign should be used only for negative numbers (this is the default behavior).
indicates that a leading space should be used on positive numbers, and a minus sign on negative numbers.
The ‘z’ option coerces negative zero floating-point values to positive zero after rounding to the format precision. This option is only valid for floating-point presentation types.
Changed in version 3.11: Added the ‘z’ option (see also PEP 682).
The ‘#’ option causes the “alternate form” to be used for the conversion. The alternate form is defined differently for different types. This option is only valid for integer, float and complex types. For integers, when binary, octal, or hexadecimal output is used, this option adds the respective prefix ‘0b’ , ‘0o’ , ‘0x’ , or ‘0X’ to the output value. For float and complex the alternate form causes the result of the conversion to always contain a decimal-point character, even if no digits follow it. Normally, a decimal-point character appears in the result of these conversions only if a digit follows it. In addition, for ‘g’ and ‘G’ conversions, trailing zeros are not removed from the result.
The ‘,’ option signals the use of a comma for a thousands separator. For a locale aware separator, use the ‘n’ integer presentation type instead.
Changed in version 3.1: Added the ‘,’ option (see also PEP 378).
The ‘_’ option signals the use of an underscore for a thousands separator for floating point presentation types and for integer presentation type ‘d’ . For integer presentation types ‘b’ , ‘o’ , ‘x’ , and ‘X’ , underscores will be inserted every 4 digits. For other presentation types, specifying this option is an error.
Changed in version 3.6: Added the ‘_’ option (see also PEP 515).
width is a decimal integer defining the minimum total field width, including any prefixes, separators, and other formatting characters. If not specified, then the field width will be determined by the content.
When no explicit alignment is given, preceding the width field by a zero ( ‘0’ ) character enables sign-aware zero-padding for numeric types. This is equivalent to a fill character of ‘0’ with an alignment type of ‘=’ .
Changed in version 3.10: Preceding the width field by ‘0’ no longer affects the default alignment for strings.
The precision is a decimal integer indicating how many digits should be displayed after the decimal point for presentation types ‘f’ and ‘F’ , or before and after the decimal point for presentation types ‘g’ or ‘G’ . For string presentation types the field indicates the maximum field size – in other words, how many characters will be used from the field content. The precision is not allowed for integer presentation types.
Finally, the type determines how the data should be presented.
The available string presentation types are:
String format. This is the default type for strings and may be omitted.
The available integer presentation types are:
Binary format. Outputs the number in base 2.
Character. Converts the integer to the corresponding unicode character before printing.
Decimal Integer. Outputs the number in base 10.
Octal format. Outputs the number in base 8.
Hex format. Outputs the number in base 16, using lower-case letters for the digits above 9.
Hex format. Outputs the number in base 16, using upper-case letters for the digits above 9. In case ‘#’ is specified, the prefix ‘0x’ will be upper-cased to ‘0X’ as well.
Number. This is the same as ‘d’ , except that it uses the current locale setting to insert the appropriate number separator characters.
In addition to the above presentation types, integers can be formatted with the floating point presentation types listed below (except ‘n’ and None ). When doing so, float() is used to convert the integer to a floating point number before formatting.
The available presentation types for float and Decimal values are:
Scientific notation. For a given precision p , formats the number in scientific notation with the letter вЂe’ separating the coefficient from the exponent. The coefficient has one digit before and p digits after the decimal point, for a total of p + 1 significant digits. With no precision given, uses a precision of 6 digits after the decimal point for float , and shows all coefficient digits for Decimal . If no digits follow the decimal point, the decimal point is also removed unless the # option is used.
Scientific notation. Same as ‘e’ except it uses an upper case вЂE’ as the separator character.
Fixed-point notation. For a given precision p , formats the number as a decimal number with exactly p digits following the decimal point. With no precision given, uses a precision of 6 digits after the decimal point for float , and uses a precision large enough to show all coefficient digits for Decimal . If no digits follow the decimal point, the decimal point is also removed unless the # option is used.
Fixed-point notation. Same as ‘f’ , but converts nan to NAN and inf to INF .
General format. For a given precision p >= 1 , this rounds the number to p significant digits and then formats the result in either fixed-point format or in scientific notation, depending on its magnitude. A precision of 0 is treated as equivalent to a precision of 1 .
The precise rules are as follows: suppose that the result formatted with presentation type ‘e’ and precision p-1 would have exponent exp . Then, if m exp p , where m is -4 for floats and -6 for Decimals , the number is formatted with presentation type ‘f’ and precision p-1-exp . Otherwise, the number is formatted with presentation type ‘e’ and precision p-1 . In both cases insignificant trailing zeros are removed from the significand, and the decimal point is also removed if there are no remaining digits following it, unless the ‘#’ option is used.
With no precision given, uses a precision of 6 significant digits for float . For Decimal , the coefficient of the result is formed from the coefficient digits of the value; scientific notation is used for values smaller than 1e-6 in absolute value and values where the place value of the least significant digit is larger than 1, and fixed-point notation is used otherwise.
Positive and negative infinity, positive and negative zero, and nans, are formatted as inf , -inf , 0 , -0 and nan respectively, regardless of the precision.
General format. Same as ‘g’ except switches to ‘E’ if the number gets too large. The representations of infinity and NaN are uppercased, too.
Number. This is the same as ‘g’ , except that it uses the current locale setting to insert the appropriate number separator characters.
Percentage. Multiplies the number by 100 and displays in fixed ( ‘f’ ) format, followed by a percent sign.
For float this is the same as ‘g’ , except that when fixed-point notation is used to format the result, it always includes at least one digit past the decimal point. The precision used is as large as needed to represent the given value faithfully.
For Decimal , this is the same as either ‘g’ or ‘G’ depending on the value of context.capitals for the current decimal context.
The overall effect is to match the output of str() as altered by the other format modifiers.
Format examples¶
This section contains examples of the str.format() syntax and comparison with the old % -formatting.
In most of the cases the syntax is similar to the old % -formatting, with the addition of the <> and with : used instead of % . For example, ‘%03.2f’ can be translated to ‘<:03.2f>‘ .
The new format syntax also supports new and different options, shown in the following examples.
Источник статьи: http://docs.python.org/3/library/string.html
Строки в python 3: методы, функции, форматирование
В уроке по присвоению типа переменной в Python вы могли узнать, как определять строки: объекты, состоящие из последовательности символьных данных. Обработка строк неотъемлемая частью программирования на python. Крайне редко приложение, не использует строковые типы данных.
Из этого урока вы узнаете: Python предоставляет большую коллекцию операторов, функций и методов для работы со строками. Когда вы закончите изучение этой документации, узнаете, как получить доступ и извлечь часть строки, а также познакомитесь с методами, которые доступны для манипулирования и изменения строковых данных.
Ниже рассмотрим операторы, методы и функции, доступные для работы с текстом.
Строковые операторы
Вы уже видели операторы + и * в применении их к числовым значениям в уроке по операторам в Python . Эти два оператора применяются и к строкам.
Оператор сложения строк +
+ — оператор конкатенации строк. Он возвращает строку, состоящую из других строк, как показано здесь:
Оператор умножения строк *
* — оператор создает несколько копий строки. Если s это строка, а n целое число, любое из следующих выражений возвращает строку, состоящую из n объединенных копий s :
Вот примеры умножения строк:
Значение множителя n должно быть целым положительным числом. Оно может быть нулем или отрицательным, но этом случае результатом будет пустая строка:
Если вы создадите строковую переменную и превратите ее в пустую строку, с помощью ‘py’ * -6 , кто-нибудь будет справедливо считать вас немного глупым. Но это сработает.
Оператор принадлежности подстроки in
Python также предоставляет оператор принадлежности, который можно использоваться для манипуляций со строками. Оператор in возвращает True , если подстрока входит в строку, и False , если нет:
Есть также оператор not in , у которого обратная логика:
Встроенные функции строк в python
Python предоставляет множество функций, которые встроены в интерпретатор. Вот несколько, которые работают со строками:
| Функция | Описание |
|---|---|
| chr() | Преобразует целое число в символ |
| ord() | Преобразует символ в целое число |
| len() | Возвращает длину строки |
| str() | Изменяет тип объекта на string |
Более подробно о них ниже.
Функция ord(c) возвращает числовое значение для заданного символа.
На базовом уровне компьютеры хранят всю информацию в виде цифр. Для представления символьных данных используется схема перевода, которая содержит каждый символ с его репрезентативным номером.
Самая простая схема в повседневном использовании называется ASCII . Она охватывает латинские символы, с которыми мы чаще работает. Для этих символов ord(c) возвращает значение ASCII для символа c :
ASCII прекрасен, но есть много других языков в мире, которые часто встречаются. Полный набор символов, которые потенциально могут быть представлены в коде, намного больше обычных латинских букв, цифр и символом.
Unicode — это современный стандарт, который пытается предоставить числовой код для всех возможных символов, на всех возможных языках, на каждой возможной платформе. Python 3 поддерживает Unicode, в том числе позволяет использовать символы Unicode в строках.
Функция ord() также возвращает числовые значения для символов Юникода:
Функция chr(n) возвращает символьное значение для данного целого числа.
chr() действует обратно ord() . Если задано числовое значение n , chr(n) возвращает строку, представляющую символ n :
chr() также обрабатывает символы Юникода:
Функция len(s) возвращает длину строки.
len(s) возвращает количество символов в строке s :
Функция str(obj) возвращает строковое представление объекта.
Практически любой объект в Python может быть представлен как строка. str(obj) возвращает строковое представление объекта obj :
Индексация строк
Часто в языках программирования, отдельные элементы в упорядоченном наборе данных могут быть доступны с помощью числового индекса или ключа. Этот процесс называется индексация.
В Python строки являются упорядоченными последовательностями символьных данных и могут быть проиндексированы. Доступ к отдельным символам в строке можно получить, указав имя строки, за которым следует число в квадратных скобках [] .
Индексация строк начинается с нуля: у первого символа индекс 0 , следующего 1 и так далее. Индекс последнего символа в python — ‘‘длина строки минус один’’.
Например, схематическое представление индексов строки ‘foobar’ выглядит следующим образом:
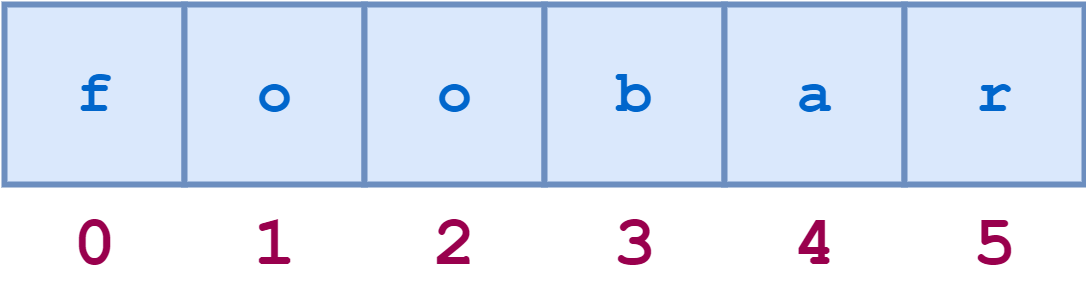
Отдельные символы доступны по индексу следующим образом:
Попытка обращения по индексу большему чем len(s) – 1 , приводит к ошибке IndexError :
Индексы строк также могут быть указаны отрицательными числами. В этом случае индексирование начинается с конца строки: -1 относится к последнему символу, -2 к предпоследнему и так далее. Вот такая же диаграмма, показывающая как положительные, так и отрицательные индексы строки ‘foobar’ :
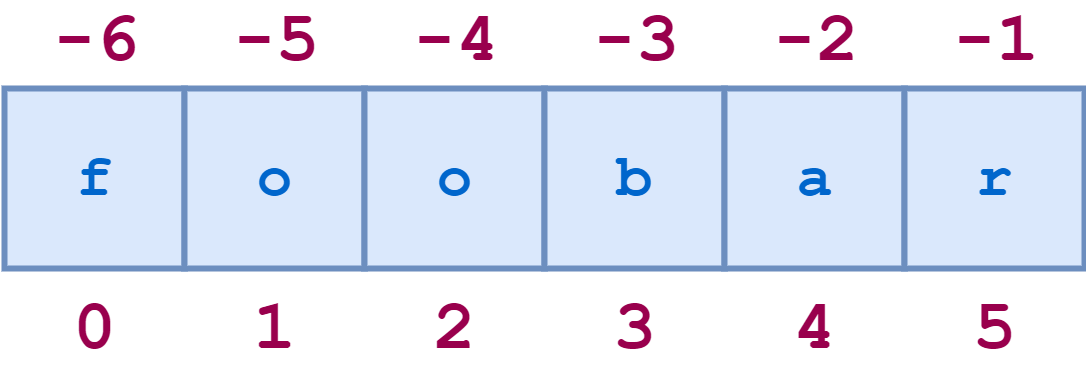
Вот несколько примеров отрицательного индексирования:
Попытка обращения по индексу меньшему чем -len(s) , приводит к ошибке IndexError :
Для любой непустой строки s , код s[len(s)-1] и s[-1] возвращают последний символ. Нет индекса, который применим к пустой строке.
Срезы строк
Python также допускает возможность извлечения подстроки из строки, известную как ‘‘string slice’’. Если s это строка, выражение формы s[m:n] возвращает часть s , начинающуюся с позиции m , и до позиции n , но не включая позицию:
Помните: индексы строк в python начинаются с нуля. Первый символ в строке имеет индекс 0 . Это относится и к срезу.
Опять же, второй индекс указывает символ, который не включен в результат. Символ ‘n’ в приведенном выше примере. Это может показаться немного не интуитивным, но дает результат: выражение s[m:n] вернет подстроку, которая является разницей n – m , в данном случае 5 – 2 = 3 .
Если пропустить первый индекс, срез начинается с начала строки. Таким образом, s[:m] = s[0:m] :
Аналогично, если опустить второй индекс s[n:] , срез длится от первого индекса до конца строки. Это хорошая, лаконичная альтернатива более громоздкой s[n:len(s)] :
Для любой строки s и любого целого n числа ( 0 ≤ n ≤ len(s) ), s[:n] + s[n:] будет s :
Пропуск обоих индексов возвращает исходную строку. Это не копия, это ссылка на исходную строку:
Если первый индекс в срезе больше или равен второму индексу, Python возвращает пустую строку. Это еще один не очевидный способ сгенерировать пустую строку, если вы его искали:
Отрицательные индексы можно использовать и со срезами. Вот пример кода Python:
Шаг для среза строки
Существует еще один вариант синтаксиса среза, о котором стоит упомянуть. Добавление дополнительного : и третьего индекса означает шаг, который указывает, сколько символов следует пропустить после извлечения каждого символа в срезе.
Например , для строки ‘python’ срез 0:6:2 начинается с первого символа и заканчивается последним символом (всей строкой), каждый второй символ пропускается. Это показано на следующей схеме:
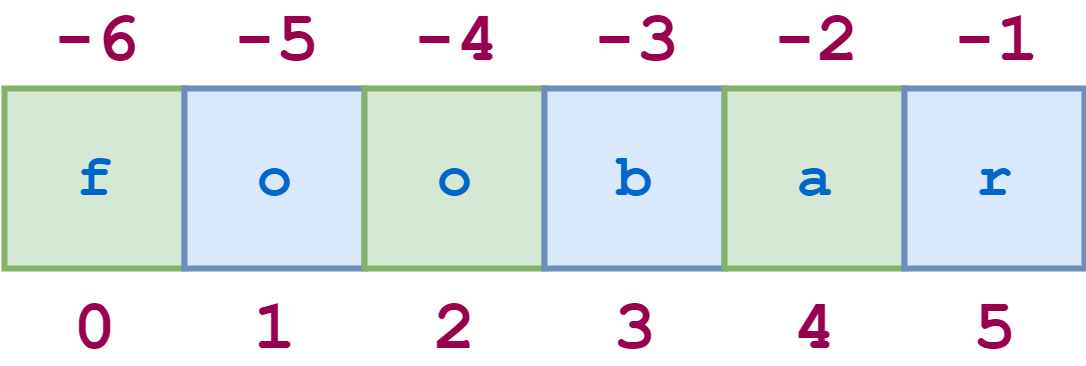
Иллюстративный код показан здесь:
Как и в случае с простым срезом, первый и второй индексы могут быть пропущены:
Вы также можете указать отрицательное значение шага, в этом случае Python идет с конца строки. Начальный/первый индекс должен быть больше конечного/второго индекса:
В приведенном выше примере, 5:0:-2 означает «начать с последнего символа и делать два шага назад, но не включая первый символ.”
Когда вы идете назад, если первый и второй индексы пропущены, значения по умолчанию применяются так: первый индекс — конец строки, а второй индекс — начало. Вот пример:
Это общая парадигма для разворота (reverse) строки:
Форматирование строки
В Python версии 3.6 был представлен новый способ форматирования строк. Эта функция официально названа литералом отформатированной строки, но обычно упоминается как f-string.
Возможности форматирования строк огромны и не будут подробно описана здесь.
Одной простой особенностью f-строк, которые вы можете начать использовать сразу, является интерполяция переменной. Вы можете указать имя переменной непосредственно в f-строковом литерале ( f’string’ ), и python заменит имя соответствующим значением.
Например, предположим, что вы хотите отобразить результат арифметического вычисления. Это можно сделать с помощью простого print() и оператора , , разделяющего числовые значения и строковые:
Но это громоздко. Чтобы выполнить то же самое с помощью f-строки:
- Напишите f или F перед кавычками строки. Это укажет python, что это f-строка вместо стандартной.
- Укажите любые переменные для воспроизведения в фигурных скобках ( <> ).
Код с использованием f-string, приведенный ниже выглядит намного чище:
Любой из трех типов кавычек в python можно использовать для f-строки:
Изменение строк
Строки — один из типов данных, которые Python считает неизменяемыми, что означает невозможность их изменять. Как вы ниже увидите, python дает возможность изменять (заменять и перезаписывать) строки.
Такой синтаксис приведет к ошибке TypeError :
На самом деле нет особой необходимости изменять строки. Обычно вы можете легко сгенерировать копию исходной строки с необходимыми изменениями. Есть минимум 2 способа сделать это в python. Вот первый:
Есть встроенный метод string.replace(x, y) :
Читайте дальше о встроенных методах строк!
Встроенные методы строк в python
В руководстве по типам переменных в python вы узнали, что Python — это объектно-ориентированный язык. Каждый элемент данных в программе python является объектом.
Вы также знакомы с функциями: самостоятельными блоками кода, которые вы можете вызывать для выполнения определенных задач.
Методы похожи на функции. Метод — специализированный тип вызываемой процедуры, тесно связанный с объектом. Как и функция, метод вызывается для выполнения отдельной задачи, но он вызывается только вместе с определенным объектом и знает о нем во время выполнения.
Синтаксис для вызова метода объекта выглядит следующим образом:
Вы узнаете намного больше об определении и вызове методов позже в статьях про объектно-ориентированное программирование. Сейчас цель усвоить часто используемые встроенные методы, которые есть в python для работы со строками.
В приведенных методах аргументы, указанные в квадратных скобках ( [] ), являются необязательными.
Изменение регистра строки
Методы этой группы выполняют преобразование регистра строки.
string.capitalize() приводит первую букву в верхний регистр, остальные в нижний.
s.capitalize() возвращает копию s с первым символом, преобразованным в верхний регистр, и остальными символами, преобразованными в нижний регистр:
Не алфавитные символы не изменяются:
string.lower() преобразует все буквенные символы в строчные.
s.lower() возвращает копию s со всеми буквенными символами, преобразованными в нижний регистр:
string.swapcase() меняет регистр буквенных символов на противоположный.
s.swapcase() возвращает копию s с заглавными буквенными символами, преобразованными в строчные и наоборот:
string.title() преобразует первые буквы всех слов в заглавные
s.title() возвращает копию, s в которой первая буква каждого слова преобразуется в верхний регистр, а остальные буквы — в нижний регистр:
Этот метод использует довольно простой алгоритм. Он не пытается различить важные и неважные слова и не обрабатывает апострофы, имена или аббревиатуры:
string.upper() преобразует все буквенные символы в заглавные.
s.upper() возвращает копию s со всеми буквенными символами в верхнем регистре:
Найти и заменить подстроку в строке
Эти методы предоставляют различные способы поиска в целевой строке указанной подстроки.
Каждый метод в этой группе поддерживает необязательные аргументы и аргументы. Они задают диапазон поиска: действие метода ограничено частью целевой строки, начинающейся в позиции символа и продолжающейся вплоть до позиции символа , но не включая его. Если указано, а нет, метод применяется к части строки от конца.
string.count([, [, ]]) подсчитывает количество вхождений подстроки в строку.
s.count() возвращает количество точных вхождений подстроки в s :
Количество вхождений изменится, если указать и :
string.endswith( [, [, ]]) определяет, заканчивается ли строка заданной подстрокой.
s.endswith( ) возвращает, True если s заканчивается указанным и False если нет:
Сравнение ограничено подстрокой, между и , если они указаны:
string.find([, [, ]]) ищет в строке заданную подстроку.
s.find() возвращает первый индекс в s который соответствует началу строки :
Этот метод возвращает, -1 если указанная подстрока не найдена:
Поиск в строке ограничивается подстрокой, между и , если они указаны:
string.index([, [, ]]) ищет в строке заданную подстроку.
Этот метод идентичен .find() , за исключением того, что он вызывает исключение ValueError , если не найден:
string.rfind([, [, ]]) ищет в строке заданную подстроку, начиная с конца.
s.rfind() возвращает индекс последнего вхождения подстроки в s , который соответствует началу :
Как и в .find() , если подстрока не найдена, возвращается -1 :
Поиск в строке ограничивается подстрокой, между и , если они указаны:
string.rindex([, [, ]]) ищет в строке заданную подстроку, начиная с конца.
Этот метод идентичен .rfind() , за исключением того, что он вызывает исключение ValueError , если не найден:
Сравнение ограничено подстрокой, между и , если они указаны:
Классификация строк
Методы в этой группе классифицируют строку на основе символов, которые она содержит.
string.isalnum() определяет, состоит ли строка из букв и цифр.
s.isalnum() возвращает True , если строка s не пустая, а все ее символы буквенно-цифровые (либо буква, либо цифра). В другом случае False :
string.isalpha() определяет, состоит ли строка только из букв.
s.isalpha() возвращает True , если строка s не пустая, а все ее символы буквенные. В другом случае False :
string.isdigit() определяет, состоит ли строка из цифр (проверка на число).
s.digit() возвращает True когда строка s не пустая и все ее символы являются цифрами, а в False если нет:
string.isidentifier() определяет, является ли строка допустимым идентификатором Python.
s.isidentifier() возвращает True , если s валидный идентификатор (название переменной, функции, класса и т.д.) python, а в False если нет:
Важно: .isidentifier() вернет True для строки, которая соответствует зарезервированному ключевому слову python, даже если его нельзя использовать:
Вы можете проверить, является ли строка ключевым словом Python, используя функцию iskeyword() , которая находится в модуле keyword . Один из возможных способов сделать это:
Если вы действительно хотите убедиться, что строку можно использовать как идентификатор python, вы должны проверить, что .isidentifier() = True и iskeyword() = False .
string.islower() определяет, являются ли буквенные символы строки строчными.
s.islower() возвращает True , если строка s не пустая, и все содержащиеся в нем буквенные символы строчные, а False если нет. Не алфавитные символы игнорируются:
string.isprintable() определяет, состоит ли строка только из печатаемых символов.
s.isprintable() возвращает, True если строка s пустая или все буквенные символы которые она содержит можно вывести на экран. Возвращает, False если s содержит хотя бы один специальный символ. Не алфавитные символы игнорируются:
Важно: Это единственный .is****() метод, который возвращает True , если s пустая строка. Все остальные возвращаются False .
string.isspace() определяет, состоит ли строка только из пробельных символов.
s.isspace() возвращает True , если s не пустая строка, и все символы являются пробельными, а False , если нет.
Наиболее часто встречающиеся пробельные символы — это пробел ‘ ‘ , табуляция ‘\t’ и новая строка ‘\n’ :
Тем не менее есть несколько символов ASCII, которые считаются пробелами. И если учитывать символы Юникода, их еще больше:
‘\f’ и ‘\r’ являются escape-последовательностями для символов ASCII; ‘\u2005’ это escape-последовательность для Unicode.
string.istitle() определяет, начинаются ли слова строки с заглавной буквы.
s.istitle() возвращает True когда s не пустая строка и первый алфавитный символ каждого слова в верхнем регистре, а все остальные буквенные символы в каждом слове строчные. Возвращает False , если нет:
string.isupper() определяет, являются ли буквенные символы строки заглавными.
s.isupper() возвращает True , если строка s не пустая, и все содержащиеся в ней буквенные символы являются заглавными, и в False , если нет. Не алфавитные символы игнорируются:
Выравнивание строк, отступы
Методы в этой группе влияют на вывод строки.
string.center( [, ]) выравнивает строку по центру.
s.center( ) возвращает строку, состоящую из s выровненной по ширине . По умолчанию отступ состоит из пробела ASCII:
Если указан необязательный аргумент , он используется как символ заполнения:
Если s больше или равна , строка возвращается без изменений:
string.expandtabs(tabsize=8) заменяет табуляции на пробелы
s.expandtabs() заменяет каждый символ табуляции ( ‘\t’ ) пробелами. По умолчанию табуляция заменяются на 8 пробелов:
tabsize необязательный параметр, задающий количество пробелов:
string.ljust( [, ]) выравнивание по левому краю строки в поле.
s.ljust( ) возвращает строку s , выравненную по левому краю в поле шириной . По умолчанию отступ состоит из пробела ASCII:
Если указан аргумент , он используется как символ заполнения:
Если s больше или равна , строка возвращается без изменений:
string.lstrip([ ]) обрезает пробельные символы слева
s.lstrip() возвращает копию s в которой все пробельные символы с левого края удалены:
Необязательный аргумент , определяет набор символов, которые будут удалены:
string.replace(
-
, [, ]) заменяет вхождения подстроки в строке.
s.replace(
-
, ) возвращает копию s где все вхождения подстроки
- Часть s до
- Разделитель
- Часть s после
- 2**31 – 1 — для 32-битной платформы;
- 2**63 – 1 — для 64-битной платформы;
- цифра условно меньше, чем любая буква из алфавита;
- алфавитная буква в верхнем регистре меньше, чем буква в нижнем регистре;
- чем раньше буква в алфавите, тем она меньше;
- ‘ %d ‘, ‘ %i ‘, ‘ %u — десятичное число;
- ‘ %c ‘ — символ, точнее строка из одного символа или число – код символа;
- ‘ %r ‘ — строка (литерал Python);
- ‘ %s ‘ — строка.
- str(n) — преобразование числового или другого типа к строке;
- len(s) — длина строки;
- chr(s) — получение символа по его коду ASCII;
- ord(s) — получение кода ASCII по символу.
- find(s, start, end) — возвращает индекс первого вхождения подстроки в s или -1 при отсутствии. Поиск идет в границах от start до end ;
- rfind(s, start, end) — аналогично, но возвращает индекс последнего вхождения;
- replace(s, new) — меняет последовательность символов s на новую подстроку new ;
- split(x) — разбивает строку на подстроки при помощи выбранного разделителя x;
- join(x) — соединяет строки в одну при помощи выбранного разделителя x;
- strip(s) — убирает пробелы с обеих сторон;
- lstrip(s), rstrip(s) — убирает пробелы только слева или справа;
- lower() — перевод всех символов в нижний регистр;
- upper() — перевод всех символов в верхний регистр;
- capitalize() — перевод первой буквы в верхний регистр, остальных — в нижний.
- Список (list) – изменяемая
- Кортеж (tuple) – неизменяемая
- Диапазон (range) – неизменяемая
- Строка (str, unicode) – неизменяемая
- Списки( list )
- Кортежи( tuple )
- Диапазоны( range ).
- Обработки двоичных данных( binary data ) и
- Текстовых строк( str ).
- Преобразование строк.
- Оценка и классификация строк.
- Конвертация регистра.
- Поиск, подсчет и замена символов.
- количество символов, содержащихся в тексте;
- True или False в зависимости от того, являются ли все символы буквами и цифрами.
- создание строк
- индексацию строк
- работу с подстроками
- использование методов строк
- при помощи оператора сложения можно сложить две строки или более
- при помощи оператора умножения можно умножать строки.
- encoding: указывает тип кодировки;
- errors: определяет ответ при ошибке кодирования;
- strict
- ignore
- replace
- xmlcharrefreplace
- backslashreplace
- Строка считается идентификатором, если она содержит буквенно-цифровые буквы (a-z, 0-9) или знаки подчеркивания.
- Идентификатор не может начинаться с цифры.
- num_characters: общая длина строки вместе с добавленными символами
- separator: символ, который добавляется в строку n раз, чтобы длина строки достигла заданного в предыдущем параметре значения
- Первый параметр a является обязательным. Если указан только он один, то он должен быть словарем, который определяет порядок замены строк. В противном случае параметр a должен быть строкой, которая показывает, какие символы нужно будет менять.
- Второй параметр b является необязательным. Он должен быть одинаковой длины с параметром a . Каждый символ в a будет заменен соответствующим символом в b .
- Третий параметр c также является необязательным. Он определяет, какие символы нужно будет удалить из исходной строки.
- old: символ или подстрока, которую вы хотите заменить
- new: то, на что вы хотите это поменять
- count: необязательный параметр (по умолчанию равен 1), определяет количество замен, которое необходимо произвести
- val: значение искомого символа или подстроки
- start: необязательный параметр, определяет индекс строки, с которого начинается поиск
- end: также необязательный параметр, определяет индекс строки, где поиск будет прекращен
- val: значение искомого символа или подстроки
- start: необязательный параметр, определяет индекс строки, с которого начинается поиск
- end: также необязательный параметр, определяет индекс строки, где поиск будет прекращен
- num_characters: общая длина строки вместе с добавленными символами
- separator: символ, который следует добавлять слева от строки до достижения нужной длины
- separator: разделитель (символ или подстрока), на основе которого разбивается строка
- max: определяет максимальное количество разбиений, это необязательный параметр, если его не задавать, то данный метод работает точно так же, как split()
- separator: необязательный параметр, символ или подстрока, на основании которой будет осуществляться разбиение
- max: также необязательный параметр, определяет количество предполагаемых разбиений
- val: значение, наличие которого хочется проверить
- start: необязательный параметр, целое число, определяющее индекс, с которого следует начать поиск
- end: также необязательный параметр, целое число, указывающее на индекс, на котором надо завершить поиск
- мобильной разработке;
- компьютерных программах;
- клиент-серверных моделях;
- формировании операционных систем;
- веб-приложениях.
- кроссплатформенность;
- отличную поддержку и дружелюбное сообщество;
- наличие динамической типизации;
- простой и понятный исходный код;
- гармонично разработанный синтаксис – с ним справится даже новичок;
- функциональность и обилие различных библиотек;
- возможность быстро обнаружить ошибки за счет интерпретируемости;
- наличие собственной системы оповещений об ошибках.
- относительная медлительность;
- не самая лучшая работа с памятью;
- строгая привязка к системным библиотекам.
- Алгоритм – инструкции и правила, которые необходимы для решения тех или иных задач.
- API – интерфейс прикладного программирования. Некие правила и процедуры, а также протоколы, используемые для формирования приложений. Помогают «общаться» со сторонними службами и другими программами.
- Аргумент – значение, передаваемое в имеющиеся функции и команды.
- Символ (char) – элементарная единица информации. Она равна одной буквенной или символьной записи.
- Объект (object) – комбинация связанных переменных, констант и иных структур информации, используемая для совместной выборки и обработки.
- Класс (class) – связанные между собой объекты с общими свойствами.
- Переменная – именованная ячейка памяти. Место хранения информации.
- Константа – значение, которое никогда не меняется. Оно остается фиксированным на протяжении всего жизненного цикла программы. Может быть выражена числом, символом или строкой (the string).
- Тип данных – классификация информации того или иного типа.
- Массив (array) – группа или список схожих типов значений данных, которые обязательно группируются.
- Исключение – особое состояние, которое возникает при выполнении исходного кода. Оно служит аномальным для приложения, нехарактерным.
- Фреймворк – блок кода, помогающий быстрее программировать. Разработчик может менять его под свои нужды, чтобы создавать однотипные приложения.
- Петля – последовательность алгоритмов, которая будет повторять написанный фрагмент кода снова и снова. Происходит это до тех пор, пока не достигнуто установленное условие. Также носит название цикла.
- Бесконечный цикл – непрерывное повторение части кода. Оно никогда не прекращается самостоятельно.
- Итерация – один проход через набор заданных операций в исходном коде.
- Ключевое слово – слова, которые зарезервированы языком, а также используются для выполнения определенных команд и задач. Могут выступать в качестве параметров.
- Операнд – объекты, которыми можно управлять при помощи операторов.
- Оператор – объект, манипулирующий разными операторами.
- условно значение true возвращается, если в the string обнаружен проверяемый элемент;
- параметр false появляется, когда в строке отсутствуют искомые компоненты.
- она начинается с 0;
- для получения доступа к конкретному символу нужно использовать запись string [i], где i – это index;
- если индекс выходит за пределы строки, на экране появится ошибка IndexError.
- в скобках пишется набор символов, по которым производится дробление;
- перед методом указывается имя строки;
- после string name ставится точка.
- startswith() – дает возможность поиска набора символа с начала;
- endswith() – используется для поиска символьного набора в конце строки.
- strip() – работает в начале и конце string;
- istrip() – отвечает за удаление пробелов в начале;
- rstrip() – убирает пробелы в конце.
- Образовательный процесс проводится в режиме онлайн. Курс рассчитан на срок от пары месяцев до года.
- Гарантируется поддержка (кураторство), даются интересные домашние задания.
- Учат программировать с нуля.
-
, заменены на :
Если указан необязательный аргумент , выполняется количество замен:
string.rjust( [, ]) выравнивание по правому краю строки в поле.
s.rjust( ) возвращает строку s , выравненную по правому краю в поле шириной . По умолчанию отступ состоит из пробела ASCII:
Если указан аргумент , он используется как символ заполнения:
Если s больше или равна , строка возвращается без изменений:
string.rstrip([ ]) обрезает пробельные символы справа
s.rstrip() возвращает копию s без пробельных символов, удаленных с правого края:
Необязательный аргумент , определяет набор символов, которые будут удалены:
string.strip([ ]) удаляет символы с левого и правого края строки.
s.strip() эквивалентно последовательному вызову s.lstrip() и s.rstrip() . Без аргумента метод удаляет пробелы в начале и в конце:
Как в .lstrip() и .rstrip() , необязательный аргумент определяет набор символов, которые будут удалены:
Важно: Когда возвращаемое значение метода является другой строкой, как это часто бывает, методы можно вызывать последовательно:
string.zfill( ) дополняет строку нулями слева.
s.zfill( ) возвращает копию s дополненную ‘0’ слева для достижения длины строки указанной в :
Если s содержит знак перед цифрами, он остается слева строки:
Если s больше или равна , строка возвращается без изменений:
.zfill() наиболее полезен для строковых представлений чисел, но python с удовольствием заполнит строку нулями, даже если в ней нет чисел:
Методы преобразование строки в список
Методы в этой группе преобразовывают строку в другой тип данных и наоборот. Эти методы возвращают или принимают итерируемые объекты — термин Python для последовательного набора объектов.
Многие из этих методов возвращают либо список, либо кортеж. Это два похожих типа данных, которые являются прототипами примеров итераций в python. Список заключен в квадратные скобки ( [] ), а кортеж заключен в простые ( () ).
Теперь давайте посмотрим на последнюю группу строковых методов.
string.join( ) объединяет список в строку.
s.join( ) возвращает строку, которая является результатом конкатенации объекта с разделителем s .
Обратите внимание, что .join() вызывается строка-разделитель s . должна быть последовательностью строковых объектов.
Примеры кода помогут вникнуть. В первом примере разделителем s является строка ‘, ‘ , а список строк:
В результате получается одна строка, состоящая из списка объектов, разделенных запятыми.
В следующем примере указывается как одно строковое значение. Когда строковое значение используется в качестве итерируемого, оно интерпретируется как список отдельных символов строки:
Таким образом, результатом ‘:’.join(‘corge’) является строка, состоящая из каждого символа в ‘corge’ , разделенного символом ‘:’ .
Этот пример завершается с ошибкой TypeError , потому что один из объектов в не является строкой:
Как вы скоро увидите, многие объекты в Python можно итерировать, и .join() особенно полезен для создания из них строк.
string.partition( ) делит строку на основе разделителя.
s.partition( ) отделяет от s подстроку длиной от начала до первого вхождения . Возвращаемое значение представляет собой кортеж из трех частей:
Вот пара примеров .partition() в работе:
Если не найден в s , возвращаемый кортеж содержит s и две пустые строки:
s.rpartition( ) делит строку на основе разделителя, начиная с конца.
s.rpartition( ) работает как s.partition( ) , за исключением того, что s делится при последнем вхождении вместо первого:
string.rsplit(sep=None, maxsplit=-1) делит строку на список из подстрок.
Без аргументов s.rsplit() делит s на подстроки, разделенные любой последовательностью пробелов, и возвращает список:
Если указан, он используется в качестве разделителя:
Если = None , строка разделяется пробелами, как если бы не был указан вообще.
Когда явно указан в качестве разделителя s , последовательные повторы разделителя будут возвращены как пустые строки:
Это не работает, когда не указан. В этом случае последовательные пробельные символы объединяются в один разделитель, и результирующий список никогда не будет содержать пустых строк:
Если указан необязательный параметр , выполняется максимальное количество разделений, начиная с правого края s :
Значение по умолчанию для — -1 . Это значит, что все возможные разделения должны быть выполнены:
string.split(sep=None, maxsplit=-1) делит строку на список из подстрок.
s.split() ведет себя как s.rsplit() , за исключением того, что при указании , деление начинается с левого края s :
Если не указано, между .rsplit() и .split() в python разницы нет.
string.splitlines([ ]) делит текст на список строк.
s.splitlines() делит s на строки и возвращает их в списке. Любой из следующих символов или последовательностей символов считается границей строки:
| Разделитель | Значение |
|---|---|
| \n | Новая строка |
| \r | Возврат каретки |
| \r\n | Возврат каретки + перевод строки |
| \v или же \x0b | Таблицы строк |
| \f или же \x0c | Подача формы |
| \x1c | Разделитель файлов |
| \x1d | Разделитель групп |
| \x1e | Разделитель записей |
| \x85 | Следующая строка |
| \u2028 | Новая строка (Unicode) |
| \u2029 | Новый абзац (Unicode) |
Вот пример использования нескольких различных разделителей строк:
Если в строке присутствуют последовательные символы границы строки, они появятся в списке результатов, как пустые строки:
Если необязательный аргумент указан и его булевое значение True , то символы границы строк сохраняются в списке подстрок:
Заключение
В этом руководстве было подробно рассмотрено множество различных механизмов, которые Python предоставляет для работы со строками, включая операторы, встроенные функции, индексирование, срезы и встроенные методы.
Python есть другие встроенные типы данных. В этих урока вы изучите два наиболее часто используемых:
Источник статьи: http://pythonru.com/osnovy/stroki-python
Строки в Python и функции для работы с ними
Строки в языке программирования Python — это объекты, которые состоят из последовательности символов.
Наравне с bool, int и другими типами данных, работа со строковым типом является неотъемлемой частью программирования, так как очень редко встречаются приложения, в которых не используется текст.
Вводная информация о строках
Как и во многих других языках программирования, в Python есть большая коллекция функций, операторов и методов, позволяющих работать со строковым типом.
Что представляют собой строки в Python
С точки зрения Питона, строка — это упорядоченная последовательность символов, которая предназначена для хранения информации в виде простого текста.
Поэтому тип данных string используется в случае, когда что-то нужно представить в текстовой форме.
Литералы строк
Литерал — способ создания объектов, в случае строк Питон предлагает несколько основных вариантов:
>>> ‘string’ # одинарные кавычки ‘string’ >>> “string” # двойные кавычки ‘string’ >>> “””string””” ‘string’ >>> ”’string”’ ‘string’
Если внутри строки необходимо расположить двойные кавычки, и сама строка была создана с помощью двойных кавычек, можно сделать следующее:
>>> ‘book “war and peace”‘ # разный тип кавычек ‘book “war and peace”‘ >>> “book ‘war and peace'” # разный тип кавычек “book ‘war and peace'” >>> “book \”war and peace\”” # экранирование кавычек одного типа ‘book “war and peace”‘ >>> ‘book \’war and peace\” # экранирование кавычек одного типа “book ‘war and peace'”
💡 Разницы между строками с одинарными и двойными кавычками нет — это одно и то же
Какие кавычки использовать — решать вам, соглашение PEP 8 не дает рекомендаций по использованию кавычек. Просто выберите один тип кавычек и придерживайтесь его. Однако если в стоке используются те же кавычки, что и в литерале строки, используйте разные типы кавычек — обратная косая черта в строке ухудшает читаемость кода.
Кодировка строк
В третьей версии языка программирования Python все строки представляют собой последовательность Unicode-символов.
В Python 3 кодировка по умолчанию исходного кода — UTF-8. Во второй версии по умолчанию использовалась ASCII. Если необходимо использовать другую кодировку, можно разместить специальное объявление на первой строке файла, к примеру:
Максимальная длина строки в Python
Максимальная длина строки зависит от платформы. Обычно это:
Константа maxsize , определенная в модуле sys :
>>> import sys >>> sys.maxsize 2147483647
Перенос строк
Перенос строки осуществляется с помощью символа \n :
>>> text = “one\ntwo\nthree” >>> print(text) one two three
Конкатенация строк
Одна из самых распространенных операций со строками — их объединение (конкатенация). Для этого используется знак + , в результате к концу первой строки будет дописана вторая:
>>> s1 = “Hello” + ” world” >>> s2 = ” world” >>> s1+s2 ‘Hello world world’
При необходимости объединения строки с числом его предварительно нужно привести тоже к строке, используя функцию str() :
>>> name = “John” >>> age = 30 >>> “Name: ” + name + “, age: ” + str(age) ‘Name: John, age: 30’
Сравнение строк
При сравнении нескольких строк рассматриваются отдельные символы и их регистр:
При этом сравниваются по очереди первые символы, затем — 2-е и так далее.
Далеко не всегда желательной является зависимость от регистра, в таком случае можно привести обе строки к одному и тому же регистру. Для этого используются функции lower() — для приведения к нижнему и upper() — к верхнему:
>>> s1 = “Intel” >>> s2 = “intel” >>> s1 == s2 False >>> s1.lower() == s2.lower() True
Пустая строка Python
Объявить пустую строку можно следующими способами:
Как удалить строку в Python
Строки, как и некоторые другие типы данных в языке Python, являются неизменяемыми объектами. При задании нового значения строке просто создается новая, с заданным значением. Для удаления строки можно воспользоваться методом replace() , заменив ее на пустую строку:
Или перезаписать переменную пустой строкой:
Обращение по индексу
Для выбора определенного символа из строки можно воспользоваться обращением по индексу, записав его в квадратных скобках:
В Python предусмотрена возможность получить доступ и по отрицательному индексу. В таком случае отсчет будет вестись от конца строки:
Форматирование строк
Часто возникает ситуация, когда необходимо создать строку, подставив в нее определенные значения, полученные во время выполнения программы. Подстановка данных в таком случае выполняется при помощи форматирования строк, сделать это можно несколькими способами.
Оператор %
Строки в Python обладают встроенной операцией, к которой можно получить доступ оператором %, что дает возможность очень просто делать форматирование. Самый простой пример — когда для подстановки нужен только один аргумент, значением будет он сам:
>>> name = “Alex” >>> ‘Hello, %s’ % name ‘Hello, Alex’
Если же для подстановки используется несколько аргументов, то значением будет кортеж со строками:
>>> ‘%d %s, %d %s’ % (6, ‘bananas’, 10, ‘lemons’) ‘6 bananas, 10 lemons’
Как видно из предыдущего примера, зависимо от типа данных для подстановки и того, что требуется получить в итоге, пишется разный формат. Наиболее часто используются:
Такой способ форматирования строк называет “старым” стилем, который в Python 3 был заменен на более удобные способы.
str.format()
В Python 3 появился более новый метод форматирования строк, который вскоре перенесли и в Python 2.7. Такой способ избавляет программиста от специального синтаксиса %-оператора. Делается все путем вызова .format() для строковой переменной. С помощью специального символа — фигурных скобок — указывается место для подстановки значения, каждая пара скобок указывает отдельное место для подстановки, значения могут быть разного типа:
>>> print(‘<>‘.format(100)) 100 >>> ‘<0>, <1>, <2>‘.format(‘one’, ‘two’, ‘three’) ‘one, two, three’ >>> ‘<2>, <1>, <0>‘.format(‘one’, ‘two’, ‘three’) ‘three, two, one’
💭 В Python 3 форматирование строк с использованием “нового стиля” является более предпочтительным по сравнению с использованием %-стиля, так как предоставляет более широкие возможности, не усложняя простые варианты использования.
f-строки (Python 3.6+)
В Python версии 3.6 появился новый метод форматирования строк — “f-строки”, с его помощью можно использовать встроенные выражения внутри строк:
>>> name = ‘Alex’ >>> f’Hello,
Такой способ форматирования очень мощный, так как дает возможность встраивать выражения:
>>> a = 5 >>> b = 10 >>> f’Five plus ten is and not <2 * (a + b)>.’ ‘Five plus ten is 15 and not 30.’
Таким образом, форматирование с помощью f-строк напоминает использование метода format(), но более гибкое, быстрое и читабельное.
Стандартная библиотека Template Strings
Еще один способ форматирования строк, который появился еще с выходом Python версии 2.4, но так и не стал популярным — использование библиотеки Template Strings. Есть поддержка передачи значения по имени, используется $-синтаксис как в языке PHP:
>>> from string import Template >>> name = “Alex” >>> age = 30 >>> s = Template(‘My name is $name. I’m $age.’) >>> print(s.substitute(name=name, age=age)) My name is Alex. I’m 30
Функции для работы со строками
Для работы со строками в Питоне предусмотрены специальные функции. Рассмотрим их:
Преобразование числового или другого типа к строке:
Методы для работы со строками
Кроме функций, для работы со строками есть немало методов:
>>> text = “Wikipedia is a Python library that makes it easy to access and parse data from Wikipedia” >>> text.find(“Wikipedia”) 0 >>> text.rfind(“Wikipedia”) 79 >>> text.replace(“from Wikipedia”, “from https://www.wikipedia.org/”) ‘Wikipedia is a Python library that makes it easy to access and parse data from https://www.wikipedia.org/’ >>> text.split(” “) [‘Wikipedia’, ‘is’, ‘a’, ‘Python’, ‘library’, ‘that’, ‘makes’, ‘it’, ‘easy’, ‘to’, ‘access’, ‘and’, ‘parse’, ‘data’, ‘from’, ‘Wikipedia’] split_text = text.split(” “) >>> “_”.join(split_text) ‘Wikipedia_is_a_Python_library_that_makes_it_easy_to_access_and_parse_data_from_Wikipedia’ >>> text = ” test ” >>> text.strip() ‘test’ >>> text.lstrip() ‘test ‘ >>> text.rstrip() ‘ test’ >>> text = “Python is a product of the Python Software Foundation” >>> text.lower() ‘python is a product of the python software foundation’ >>> text.upper() ‘PYTHON IS A PRODUCT OF THE PYTHON SOFTWARE FOUNDATION’ >>> text = “python is a product of the python software foundation” >>> text.capitalize() ‘Python is a product of the python software foundation’
Преобразование из строки в другой тип
В Питоне строки можно преобразовывать в другие типы данных:
string → int
Функция int() преобразовывает целое число в десятичной системе, заданное как строка, в тип int:
При необходимости можно указывать систему счисления:
string → list
Самый простой способ преобразования строки в список строк — метод split() :
>>> ‘one two three four’.split() [‘one’, ‘two’, ‘three’, ‘four’]
При необходимости можно указывать разделитель:
>>> ‘one, two, three, four’.split(‘,’) [‘one’, ‘ two’, ‘ three’, ‘ four’]
string → bytes
Преобразование строкового типа в байтовый выполняется функцией encode() с указанием кодировки:
string → datetime
Строка в дату преобразовывается функцией strptime() из стандартного модуля datetime :
>>> from datetime import datetime >>> print(datetime.strptime(‘Jan 1 2020 1:33PM’, ‘%b %d %Y %I:%M%p’)) 2020-01-01 13:33:00
string → float
Для преобразования строки в число с плавающей точкой используется стандартная функция float :
string → dict
Создание словаря из строки возможно, если внутри нее данные в формате json. Для этого можно воспользоваться модулем json :
string → json
Конвертация объектов Python в объект json выполняется функцией dumps() :
>>> import json >>> json.dumps(“hello”) ‘”hello”‘
Best practices
Как разбить строку на символы
Разбиение строки на отдельные символы выполняется несколькими способами:
>>> text = “django” # вариант 1 >>> list(text) [‘d’, ‘j’, ‘a’, ‘n’, ‘g’, ‘o’] # вариант 2 >>> [c for c in “text”] [‘t’, ‘e’, ‘x’, ‘t’] # вариант 3 >>> for c in text: print(c) d j a n g o
Как из строки выделить числа
Для извлечения чисел из строки можно воспользоваться методами строк:
>>> str = “h3110 23 cat 444.4 rabbit 11 2 dog” >>> [int(s) for s in str.split() if s.isdigit()] [23, 11, 2]
Данный пример извлекает только целые положительные числа. Более универсальный вариант – регулярные выражения:
>>> str = “h3110 23 cat 444.4 rabbit 11 2 dog” >>> import re >>> re.findall(r’\d+’, str) [‘3110′, ’23’, ‘444’, ‘4’, ’11’, ‘2’]
Как перевернуть строку
Существует несколько способов перевернуть строку, начиная от классического – запустить цикл в обратной последовательности, выбирая каждый символ с конца и вставляя его в новую строку, и заканчивая срезами – вариант только для Питона.
С помощью среза — самый быстрый способ:
Использование reversed() и str.join() :
Как удалить последний символ в строке
Как и в предыдущем случае – чтобы убрать последний символ наиболее простым и быстрым вариантом будет использование среза:
Как убрать пробелы из строки
В случае удаления пробелов со строки может быть два варианта:
1 Обрезать строку так, чтобы удалить с нее первый и последний пробел, такой вариант может пригодиться, когда пользователь случайно поставит пробел в конце введенного текста:
>>> ” Some text “.strip() ‘Some text’
2 Удалить со строки все пробелы:
>>> ” So me t e x t “.replace(‘ ‘, ”) ‘Sometext’
Работа со строками — неотъемлемая часть создания практически любого приложения, где используется текст, и язык программирования Python предоставляет широкие возможности работы с такими данными.
Источник статьи: http://pythonchik.ru/osnovy/python-stroki
Урок 4
Работа со строками

Последовательности в Python
Последовательность(Sequence Type) — итерируемый контейнер, к элементам которого есть эффективный доступ с использованием целочисленных индексов.
Последовательности могут быть как изменяемыми, так и неизменяемыми. Размерность и состав созданной однажды неизменяемой последовательности не может меняться, вместо этого обычно создаётся новая последовательность.
Примеры последовательностей в стандартной библиотеке Python:
2. С помощью тройных кавычек.
Главное достоинство строк в тройных кавычках в том, что их можно использовать для записи многострочных блоков текста. Внутри такой строки возможно присутствие кавычек и апострофов, главное, чтобы не было трех кавычек подряд. Пример:


Экранированные последовательности – это служебные наборы символов, которые позволяют вставить нестандартные символы, которые сложно ввести с клавиатуры.
В таблице перечислены самые часто используемые экранированные последовательности:
“Сырые строки”
Если перед открывающей кавычкой стоит символ ‘r’ (в любом регистре), то механизм экранирования отключается.
Это может быть нужно, например, в такой ситуации:
str = r’C:\new_file.txt’


Итак, строки в Python поддерживают две группы методов:
Группа 1.Общие методы для всех Sequence Type данных.
В Python cуществуют 3 базовых типа Последовательностей(Sequence Type):
И также есть дополнительные типы последовательностей для:
Все эти типы данных(базовые и дополнительные) поддерживают общую группу операций. Например:


Далее будем рассматривать базовые операции, которые можно выполнять со строками. Начнем со сложения и умножения строк. Они, как мы уже выяснили выше, относятся к группе общих операций над последовательностями. Итак:
1. Оператор сложения строк +
+ — оператор конкатенации строк. Он возвращает строку, состоящую из совокупности других строк.
Например:

Срезы так же относятся к группе общих операций – они используются для всех последовательностей, а значит и для строковых переменных. Рассмотрим подробнее, что это такое и с чем его едят.
Срез (slice) — извлечение из данной строки одного символа или некоторого фрагмента подстроки или подпоследовательности.
Индекс – номер символа в строке (а также в других структурах данных: списках, кортежах). Обратите внимание, что нумерация начинается с 0 . Если указать отрицательное значение индекса, то номер будет отсчитываться с конца, начиная с номера -1 .
Есть три формы срезов:
1. Самая простая форма среза – взятие одного символа строки – S[i] , где S – строка, i – индекс. Пример:

Задачи по темам

Функции поиска
Как вы уже могли заметить, в Python существует две похожих функции для поиска подстроки – find() (относится к группе строковых методов) и index() (общий метод для SequenceType данных) . Разница в том, что find() вернет -1 , если не найдет искомое, а index() выкинет исключение ValueError .
Кроме того, необходимо помнить, что если нужно только удостовериться, что подстрока присутствует внутри строки – можно просто воспользоваться методом in :
>>> ‘Py’ in ‘Python’
True


В Python версии 3.6 был представлен новый способ форматирования строк. Эта функция официально названа литералом отформатированной строки, но обычно упоминается как f-string . Способов форматирования в Python довольно много, но работу с f-строками мы считаем самым удобным и перспективным способом, поэтому рассмотрим именно его.
Одной простой особенностью f-строк, которую вы можете начать использовать сразу, является интерполяция переменной. Вы можете указать имя переменной непосредственно в f-строковом литерале ( f’string’ ), и Python заменит имя соответствующим значением.
Например, предположим, что вы хотите отобразить результат арифметического вычисления. Это можно сделать с помощью простого print() и оператора , , разделяющего числовые значения и строковые:
Источник статьи: http://smartiqa.ru/courses/python/lesson-4
🐍 Самоучитель по Python для начинающих. Часть 4. Методы работы со строками

Текстовые переменные str в Питоне
Строковый тип str в Python используют для работы с любыми текстовыми данными. Python автоматически определяет тип str по кавычкам – одинарным или двойным:
Для решения многих задач строковую переменную нужно объявить заранее, до начала исполнения основной части программы. Создать пустую переменную str просто:
Если в самой строке нужно использовать кавычки – например, для названия книги – то один вид кавычек используют для строки, второй – для выделения названия:
Использование одного и того же вида кавычек внутри и снаружи строки вызовет ошибку:
Кроме двойных ” и одинарных кавычек ‘ , в Python используются и тройные ”’ – в них заключают текст, состоящий из нескольких строк, или программный код:
Длина строки len в Python
Для определения длины строки используется встроенная функция len(). Она подсчитывает общее количество символов в строке, включая пробелы:
Преобразование других типов данных в строку
Целые и вещественные числа преобразуются в строки одинаково:
Решение многих задач значительно упрощается, если работать с числами в строковом формате. Особенно это касается заданий, где нужно разделять числа на разряды – сотни, десятки и единицы.
Сложение и умножение строк
Как уже упоминалось в предыдущей главе, строки можно складывать – эта операция также известна как конкатенация:
При необходимости строку можно умножить на целое число – эта операция называется репликацией:
Подстроки
Подстрокой называется фрагмент определенной строки. Например, ‘abra’ является подстрокой ‘abrakadabra’. Чтобы определить, входит ли какая-то определенная подстрока в строку, используют оператор in :
Индексация строк в Python
Для обращения к определенному символу строки используют индекс – порядковый номер элемента. Python поддерживает два типа индексации – положительную, при которой отсчет элементов начинается с 0 и с начала строки, и отрицательную, при которой отсчет начинается с -1 и с конца:
| Положительные индексы | 0 | 1 | 2 | 3 | 4 | 5 | 6 |
| Пример строки | P | r | o | g | l | i | b |
| Отрицательные индексы | -7 | -6 | -5 | -4 | -3 | -2 | -1 |
Чтобы получить определенный элемент строки, нужно указать его индекс в квадратных скобках:
Срезы строк в Python
Индексы позволяют работать с отдельными элементами строк. Для работы с подстроками используют срезы, в которых задается нужный диапазон:
Диапазон среза [a:b] начинается с первого указанного элемента а включительно, и заканчивается на последнем, не включая b в результат:
Если не указать первый элемент диапазона [:b] , срез будет выполнен с начала строки до позиции второго элемента b:
В случае отсутствия второго элемента [a:] срез будет сделан с позиции первого символа и до конца строки:
Если не указана ни стартовая, ни финальная позиция среза, он будет равен исходной строке:
Шаг среза
Помимо диапазона, можно задавать шаг среза. В приведенном ниже примере выбирается символ из стартовой позиции среза, а затем каждая 3-я буква из диапазона:
Шаг может быть отрицательным – в этом случае символы будут выбираться, начиная с конца строки:
Срез [::-1] может оказаться очень полезным при решении задач, связанных с палиндромами:
Замена символа в строке
Строки в Python относятся к неизменяемым типам данных. По этой причине попытка замены символа по индексу обречена на провал:
Но заменить любой символ все-таки можно – для этого придется воспользоваться срезами и конкатенацией. Результатом станет новая строка:
Более простой способ «замены» символа или подстроки – использование метода replace(), который мы рассмотрим ниже.
Полезные методы строк
Python предоставляет множество методов для работы с текстовыми данными. Все методы можно сгруппировать в четыре категории:
Рассмотрим эти методы подробнее.
Преобразование строк
Три самых используемых метода из этой группы – join(), split() и partition(). Метод join() незаменим, если нужно преобразовать список или кортеж в строку:
При объединении списка или кортежа в строку можно использовать любые разделители:
Метод split() используется для обратной манипуляции – преобразования строки в список:
По умолчанию split() разбивает строку по пробелам. Но можно указать любой другой символ – и на практике это часто требуется:
Метод partition() поможет преобразовать строку в кортеж:
В отличие от split(), partition() учитывает только первое вхождение элемента-разделителя (и добавляет его в итоговый кортеж).
Оценка и классификация строк
В Python много встроенных методов для оценки и классификации текстовых данных. Некоторые из этих методов работают только со строками, в то время как другие универсальны. К последним относятся, например, функции min() и max():
В Python есть специальные методы для определения типа символов. Например, isalnum() оценивает, состоит ли строка из букв и цифр, либо в ней есть какие-то другие символы:
Метод isalpha() поможет определить, состоит ли строка только из букв, или включает специальные символы, пробелы и цифры:
С помощью метода isdigit() можно определить, входят ли в строку только цифры, или там есть и другие символы:
Поскольку вещественные числа содержат точку, а отрицательные – знак минуса, выявить их этим методом не получится:
Если нужно определить наличие в строке дробей или римских цифр, подойдет метод isnumeric():
Методы islower() и isupper() определяют регистр, в котором находятся буквы. Эти методы игнорируют небуквенные символы:
Метод isspace() определяет, состоит ли анализируемая строка из одних пробелов, или содержит что-нибудь еще:
Конвертация регистра
Как уже говорилось выше, строки относятся к неизменяемым типам данных, поэтому результатом любых манипуляций, связанных с преобразованием регистра или удалением (заменой) символов будет новая строка.
Из всех методов, связанных с конвертацией регистра, наиболее часто используются на практике два – lower() и upper(). Они преобразуют все символы в нижний и верхний регистр соответственно:
Иногда требуется преобразовать текст так, чтобы с заглавной буквы начиналось только первое слово предложения:
Методы swapcase() и title() используются реже. Первый заменяет исходный регистр на противоположный, а второй – начинает каждое слово с заглавной буквы:
Поиск, подсчет и замена символов
Методы find() и rfind() возвращают индекс стартовой позиции искомой подстроки. Оба метода учитывают только первое вхождение подстроки. Разница между ними заключается в том, что find() ищет первое вхождение подстроки с начала текста, а rfind() – с конца:
Такие же результаты можно получить при использовании методов index() и rindex() – правда, придется предусмотреть обработку ошибок, если искомая подстрока не будет обнаружена:
Если нужно определить, начинается ли строка с определенной подстроки, поможет метод startswith():
Чтобы проверить, заканчивается ли строка на нужное окончание, используют endswith():
Для подсчета числа вхождений определенного символа или подстроки применяют метод count() – он помогает подсчитать как общее число вхождений в тексте, так и вхождения в указанном диапазоне:
Методы strip(), lstrip() и rstrip() предназначены для удаления пробелов. Метод strip() удаляет пробелы в начале и конце строки, lstrip() – только слева, rstrip() – только справа:
Метод replace() используют для замены символов или подстрок. Можно указать нужное количество замен, а сам символ можно заменить на пустую подстроку – проще говоря, удалить:
Стоит заметить, что метод replace() подходит лишь для самых простых вариантов замены и удаления подстрок. В более сложных случаях необходимо использование регулярных выражений, которые мы будем изучать позже.
Практика
Задание 1
Напишите программу, которая получает на вход строку и выводит:
Задание 2
Напишите программу, которая получает на вход слово и выводит True, если слово является палиндромом, или False в противном случае. Примечание: для сравнения в Python используется оператор == .
Задание 3
Напишите программу, которая получает строку с именем, отчеством и фамилией, написанными в произвольном регистре, и выводит данные в правильном формате. Например, строка алеКСандр СЕРГЕЕВИЧ ПушкиН должна быть преобразована в Александр Сергеевич Пушкин .
Задание 4
Имеется строка 12361573928167047230472012. Напишите программу, которая преобразует строку в текст один236один573928один670472304720один2.
Задание 5
Напишите программу, которая последовательно получает на вход имя, отчество, фамилию и должность сотрудника, а затем преобразует имя и отчество в инициалы, добавляя должность после запятой.
Задание 6
Напишите программу, которая получает на вход строку текста и букву, а затем определяет, встречается ли данная буква (в любом регистре) в тексте. В качестве ответа программа должна выводить True или False.
Задание 7
Напишите программу, которая определяет, является ли введенная пользователем буква гласной. В качестве ответа программы выводит True или False, буквы могут быть как в верхнем, так и в нижнем регистре.
Задание 8
Напишите программу, которая принимает на вход строку текста и подстроку, а затем выводит индексы первого вхождения подстроки с начала и с конца строки (без учета регистра).
Задание 9
Напишите программу для подсчета количества пробелов и непробельных символов в введенной пользователем строке.
Задание 10
Напишите программу, которая принимает строку и две подстроки start и end, а затем определяет, начинается ли строка с фрагмента start, и заканчивается ли подстрокой end. Регистр не учитывать.
Подведем итоги
В этой части мы рассмотрели самые популярные методы работы со строками – они пригодятся для решения тренировочных задач и в разработке реальных проектов. В следующей статье будем разбирать методы работы со списками.
Источник статьи: http://proglib.io/p/samouchitel-po-python-dlya-nachinayushchih-chast-4-metody-raboty-so-strokami-2022-10-24
3.1. Строки, кортежи, списки
В первой главе мы познакомились с таким типом данных, как строка ( str ). Мы умеем складывать строки, умножать их на число и даже сравнивать между собой.
Если рассмотреть строку детальнее, то она состоит из символов, каждый из которых стоит на своём месте. Другими словами, строка — упорядоченная последовательность (коллекция) символов.
Слово «коллекция» в Python применяется не только к строкам. Коллекциями в Python также называют типы данных, в которых можно хранить сразу несколько значений.
В упорядоченных коллекциях, к которым относится строка, каждое значение автоматически имеет свой номер — индекс. Индексация в коллекциях Python начинается со значения 0. При этом пробел, запятая, управляющие символы \n , \t и прочие тоже получают свой индекс в строке. Для доступа к определённому символу строки по индексу нужно указать его в квадратных скобках сразу после имени переменной.
Давайте создадим программу, которая выводит первый символ строки, введённой пользователем:
Если пользователь введёт пустую строку, то наша программа выдаст ошибку:
В пустой строке нет символов, и программа вышла за пределы строки. Таким образом, нельзя получить значение по индексу, который за пределами строки. Перед обращением к символу строки по индексу можно проверять, не выходит ли он за пределы строки, используя известную нам функцию len следующим образом:
Давайте подумаем, как можно взять последний символ строки? Для этого нам потребуется воспользоваться функцией len :
Однако в Python можно упростить эту запись, убрав из неё функцию len . И тогда в качестве индекса просто будет использоваться отрицательное число:
Таким образом, последний символ имеет индекс -1, предпоследний -2 и т. д.
Так как строка — упорядоченная коллекция, то можно пройти по этой коллекции в цикле, указав в качестве индекса итерируемую переменную цикла. Например, вывести на строке каждый символ введённой пользователем строки:
Существует и другой способ пройти по символам строки в цикле. Если не требуется на каждой итерации цикла знать индекс текущего символа, то цикл можно оформить следующим образом:
При такой записи цикла программа проходит не по индексам строки, а непосредственно по её символам. Так, переменная letter на каждой итерации цикла принимает значение очередного символа строки text .
Если требуется совместить проход непосредственно по символам строки с определением индекса итерации, то можно воспользоваться функцией enumerate . Она возвращает пары значений — номер элемента коллекции и сам этот элемент. Эта функция удобна, когда нужно пройти именно по элементам коллекции, но при этом ещё и знать индекс каждого элемента.
Для строк в Python существует ещё одна полезная операция — срез ( slice ).
Срез позволяет взять часть строки, указав начальный и конечный индексы (конечный индекс не включается в диапазон). Также можно указать шаг, с которым срез будет взят (по умолчанию шаг 1). Например, в одной из прошлых глав мы аналогичным образом использовали функцию range .
Кроме того, в срезах можно использовать отрицательную индексацию. А если срез выходит за пределы строки, то программа не упадёт с ошибкой, а просто вернёт существующую часть строки.
Следующий пример показывает возможные варианты использования срезов:
Обратите внимание: строка является неизменяемой коллекцией. Это означает, что изменить отдельный символ строки нельзя.
Например, попытаемся в следующей программе изменить значение одного из символов строки:
Мы уже знаем, что взаимодействовать с переменными в Python можно с помощью операций и функций. Рассмотрим ещё один способ взаимодействия — методы.
Методы похожи на функции, но вызываются не сами по себе, а для конкретной переменной. Для каждого типа данных есть свой набор методов. Чтобы вызвать метод, его нужно указать через точку после имени переменной. В круглых скобках после имени метода дополнительно можно обозначить аргументы (параметры) вызываемого метода, как это делаем с функциями.
Например, у строк есть метод islower(), который проверяет, что в строке не встречаются большие буквы, и возвращает в таком случае значение True, иначе — False:
В следующей таблице перечислены часто используемые методы строк и примеры их работы. Важный момент: методы строк не меняют исходную строку, а возвращают новое значение, которое можно сохранить в переменной.
str.capitalize()
| Метод | str.capitalize() |
| Описание | Возвращает копию строки, у которой первая буква заглавная, а остальные приведены к строчным |
| Пример | s = “hello, World!” s.capitalize() |
| Результат | Hello, world! |
str.count(sub)
| Метод | str.count(sub) |
| Описание | Возвращает количество неперекрывающихся вхождений подстроки sub . К примеру, если искать в строке «ААААА» неперекрывающиеся значения «АА», то первое вхождение будет «AAAAA». Второе — «AAAAA». Больше неперекрывающихся вхождений нет. Так, поиск последующих вхождений подстроки происходит с индекса, который следует за последним найденным вхождением |
| Пример | s = “Hello, world!” s.count(“l”) |
| Результат | 3 |
str.endswith(suffix)
| Метод | str.endswith(suffix) |
| Описание | Возвращает True, если строка оканчивается на подстроку suffix . Иначе возвращает False. suffix может быть кортежем проверяемых окончаний строки |
| Пример | s = “Hello, world!” s.endswith(“world!”) |
| Результат | True |
str.find(sub)
| Метод | str.find(sub) |
| Описание | Возвращает индекс первого вхождения подстроки sub . Если подстрока не найдена, то возвращает -1 |
| Пример | s = “Hello, world!” s.find(“o”) |
| Результат | 4 |
str.index(sub)
| Метод | str.index(sub) |
| Описание | Возвращает индекс первого вхождения подстроки sub . Вызывает исключение ValueError, если подстрока не найдена. Тема ошибок (исключений) будет разбираться на одной из следующих глав |
| Пример | s = “Hello, world!” s.index(“o”) |
| Результат | 4 |
str.isalnum()
| Метод | str.isalnum() |
| Описание | Возвращает True, если все символы строки являются буквами и цифрами и в строке есть хотя бы один символ. Иначе возвращает False |
| Пример | s = “abc123” s.isalnum() |
| Результат | True |
str.isalpha()
| Метод | str.isalpha() |
| Описание | Возвращает True, если все символы строки являются буквами и в строке есть хотя бы один символ. Иначе возвращает False |
| Пример | s = “Letters” s.isalpha() |
| Результат | True |
str.isdigit()
| Метод | str.isdigit() |
| Описание | Возвращает True, если все символы строки являются цифрами и в строке есть хотя бы один символ. Иначе возвращает False |
| Пример | s = “123” s.isdigit() |
| Результат | True |
str.islower()
| Метод | str.islower() |
| Описание | Возвращает True, если все буквы в строке маленькие и в строке есть хотя бы одна буква. Иначе возвращает False |
| Пример | s = “word123” s.islower() |
| Результат | True |
str.isupper()
| Метод | str.isupper() |
| Описание | Возвращает True, если все буквы в строке большие и в строке есть хотя бы одна буква. Иначе возвращает False |
| Пример | s = “WORD123” s.isupper() |
| Результат | True |
str.join(str_col)
| Метод | str.join(str_col) |
| Описание | Возвращает строку, полученную конкатенацией (сложением) строк — элементов коллекции str_col (обозначение коллекции с элементами типа данных «строка»). Разделителем является строка, для которой вызван метод |
| Пример | a = [“1”, “2”, “3”] “; “.join(a) |
| Результат | “1; 2; 3” |
str.ljust(width, fillchar)
| Метод | str.ljust(width, fillchar) |
| Описание | Возвращает строку длиной width с выравниванием по левому краю. Строка дополняется справа символами fillchar до требуемой длины. По умолчанию значение fillchar — пробел |
| Пример | s = “text” s.ljust(10, “=”) |
| Результат | “text======” |
str.rstrip(chars)
| Метод | str.rstrip(chars) |
| Описание | Возвращает строку, у которой в конце удалены символы, встречающиеся в строке chars . Если значение chars не задано, то пробельные символы удаляются |
| Пример | s = “stringBCCA” s.rstrip(“ABC”) |
| Результат | “string” |
str.split(sep)
| Метод | str.split(sep) |
| Описание | Возвращает список строк по разделителю sep . По умолчанию sep — любое количество пробельных символов |
| Пример | s = “one, two, three” s.split(“, “) |
| Результат | [“one”, “two”, “three”] |
str.startswith(prefix)
| Метод | str.startswith(prefix) |
| Описание | Возвращает True, если строка начинается на подстроку prefix , иначе возвращает False. prefix может быть кортежем проверяемых префиксов строки. Под кортежами подразумевается неизменяемая последовательность элементов |
| Пример | s = “Hello, world!” s.startswith(“Hello”) |
| Результат | True |
str.strip(chars)
| Метод | str.strip(chars) |
| Описание | Возвращает строку, у которой в начале и в конце удалены символы, встречающиеся в строке chars . Если значение chars не задано, то пробельные символы удаляются |
| Пример | s = “abc Hello, world! cba” s.strip(” abc”) |
| Результат | “Hello, world!” |
str.title()
| Метод | str.title() |
| Описание | Возвращает строку, в которой каждое отдельное слово начинается с буквы в верхнем регистре, а остальные буквы идут в нижнем |
| Пример | s = “hello, world!” s.title() |
| Результат | “Hello, World!” |
str.upper()
| Метод | str.upper() |
| Описание | Возвращает копию строки, у которой все буквы приведены к верхнему регистру |
| Пример | s = “Hello, world!” s.upper() |
| Результат | “HELLO, WORLD!” |
str.zfill(width)
| Метод | str.zfill(width) |
| Описание | Возвращает строку, дополненную слева символами «0» до длины width |
| Пример | s = “123” s.zfill(5) |
| Результат | “00123” |
Рассмотрим ещё одну коллекцию в Python — список ( list ). Этот тип данных является упорядоченной коллекцией, которая может в качестве элементов иметь значения любого типа данных.
Один из способов создания списков — перечислить его элементы в квадратных скобках и присвоить это значение переменной, которая и станет в итоге списком в программе:
В примере мы создали список, состоящий из трёх элементов — целых чисел. Список может хранить значения любого типа, поэтому можно создать список со следующими элементами:
Индексация в списках работает так же, как и в строках, — начальный индекс 0. Можно использовать отрицательные индексы, а также доступны срезы:
Результат работы программы:
В отличие от строки, список относится к изменяемой коллекции. У списка можно изменить отдельный элемент, добавить новые или удалить существующие. Для изменения существующего элемента нужно указать его в левой части операции присваивания, а в правой указать новое значение этого элемента:
Если требуется добавить элемент в конец списка, то можно использовать метод append().
Например, напишем программу, в которой список последовательно заполняется 10 целочисленными значениями с клавиатуры:
Для удаления элемента из списка применяется операция del. Нужно указать индекс элемента, который требуется удалить:
С помощью del можно удалить несколько элементов списка. Для этого вместо одного элемента указываем срез:
Полезные методы и функции списков и примеры их работы приведены в следующей таблице.
| Операция | Описание | Пример | Результат |
|---|---|---|---|
| x in s | Возвращает True, если в списке s есть элемент x. Иначе False | 1 in [1, 2, 3] | True |
| x not in s | Возвращает False, если в списке s есть элемент x. Иначе True | 4 not in [1, 2, 3] | True |
| s + t | Возвращает список, полученный конкатенацией списков s и t | [1, 2] + [3, 4, 5] | [1, 2, 3, 4, 5] |
| s * n (n * s) | Возвращает список, полученный дублированием n раз списка s | [1, 2, 3] * 3 | [1, 2, 3, 1, 2, 3, 1, 2, 3] |
| len(s) | Возвращает длину списка s | len([1, 2, 3]) | 3 |
| min(s) | Возвращает минимальный элемент списка | min([1, 2, 3]) | 1 |
| max(s) | Возвращает максимальный элемент списка | max([1, 2, 3]) | 3 |
| s.index(x) | Возвращает индекс первого найденного элемента x. Вызывается исключение ValueError, если элемент не найден | [1, 2, 3, 2, 1].index(2) | 1 |
| s.count(x) | Возвращает количество элементов x | [1, 1, 1, 2, 3, 1].count(1) | 4 |
| s.append(x) | Добавляет элемент x в конец списка | s = [1, 2] s.append(3) print(s) |
[1, 2, 3] |
| s.clear() | Удаляет все элементы списка | s = [1, 2, 3] s.clear() print(s) |
[] |
| s.copy() | Возвращает копию списка | [1, 2, 3].copy() | [1, 2, 3] |
| s.extend(t) или s += t | Расширяет список s элементами списка t | s = [1, 2, 3] s.extend([4, 5]) print(s) |
[1, 2, 3, 4, 5] |
| s.insert(i, x) | Вставляет элемент x в список по индексу i | s = [1, 3, 4] s.insert(1, 2) print(s) |
[1, 2, 3, 4] |
| s.pop(i) | Возвращает и удаляет элемент с индексом i. Если i не указан, то возвращается и удаляется последний элемент | s = [1, 2, 3] x = s.pop() print(x) print(s) |
3 [1, 2] |
| s.remove(x) | Удаляет первый элемент со значением x | s = [1, 2, 3, 2, 1] s.remove(2) print(s) |
[1, 3, 2, 1] |
| s.reverse() | Меняет порядок элементов списка на противоположный (переворачивает список) | s = [1, 2, 3] s.reverse() print(s) |
[3, 2, 1] |
| s.sort() | Сортирует список по возрастанию, меняя исходный список. Для сортировки по убыванию используется дополнительный аргумент reverse=True | s = [2, 3, 1] s.sort() print(s) |
[1, 2, 3] |
| sorted(s) | Возвращает отсортированный по возрастанию список, не меняя исходный. Для сортировки по убыванию используется дополнительный аргумент reverse=True | s = [2, 3, 1] new_s = sorted(s, reverse=True) print(new_s) |
[3, 2, 1] |
Ещё одной коллекцией в Python является кортеж ( tuple ). Кортеж является неизменяемой упорядоченной коллекцией. В кортеже нельзя заменить значение элемента, добавить или удалить элемент. Простыми словами, кортеж — неизменяемый список. Свойство неизменяемости используется для защиты от случайных или намеренных изменений.
Задать кортеж можно следующим образом:
Если нужно создать кортеж из одного элемента, то запись будет такой:
Запятая в примере показывает, что в скобках не совершается операция, а идёт перечисление элементов кортежа.
Для кортежей доступны те операции и методы списков, которые не изменяют исходный кортеж.
В качестве примера использования кортежей приведём программу для обмена значений двух переменных:
Между коллекциями можно производить преобразования. Покажем их на примере преобразования строки в список и кортеж (элементы строки, символы становятся элементами списка и кортежа соответственно):
Обратите внимание: преобразование коллекций к типу данных str не объединяет элементы этой коллекции в одну строку, а возвращает представление коллекции в виде строки.
Источник статьи: http://academy.yandex.ru/handbook/python/article/stroki-kortezhi-spiski
Строки в Python
В языке Python строки — это тип данных, который используется для представления текста. Это один из базовых типов, с которым мы имеем дело в каждом проекте на Python.
Данная статья является полным руководством по использованию строк в Python. Прочитав ее, вы узнаете, как создавать строки и работать с ними. В частности, мы рассмотрим:
Как создавать строки в Python
В Python вы можете создать строку, используя двойные или одинарные кавычки.
Когда дело доходит до выбора одинарных или двойных кавычек, нужно быть последовательным. То есть вы можете использовать и те, и другие, но придерживайтесь одного стиля во всем проекте.
Применять строки и производить различные манипуляции с ними вам придется часто. Что касается «манипуляций», со строками можно делать множество вещей. Например, объединять, нарезать, изменять, находить подстроки и многое другое.
Далее поговорим об операторах строк.
Операторы строк
Возможно вы уже знаете об основных математических операторах Python.
От редакции Pythonist. На эту тему у нас есть статья «Операторы в Python».
С известной аккуратностью операторы сложения и умножения можно также применять и для строк:
В дополнении к этим двум операторам есть еще один, очень полезный. Он называется оператор in . С его помощью можно проверить, содержит ли строка определенную подстроку или символ.
Давайте рассмотрим подробнее, как работают эти операторы.
Оператор +
В Python вы можете объединить две или более строк с помощью оператора сложения (+).
Оператор *
Чтобы умножать строки в Python, можно использовать оператор умножения (*).
Оператор in
В Python оператор in можно использовать для проверки нахождения подстроки в строке.
Другими словами, с его помощью можно узнать, есть ли внутри строки определенное слово или символ.
Оператор in возвращает значение True , если внутри строки есть проверяемая подстрока. В противном случае возвращается значение False .
Теперь давайте рассмотрим другой пример. На этот раз проверим, есть ли в слове определенный символ:
Далее поговорим про индексацию строк.
Индексация строк
В Python строка представляет собой набор символов. Каждый символ строки имеет индекс — порядковый номер.
Благодаря этой индексации можно получить доступ к конкретному символу в данной строке, что весьма удобно.
Индексация строк Python начинается с нуля.
Это означает, что 1-й символ строки имеет индекс 0, 2-й символ имеет индекс 1 и так далее.
Чтобы получить доступ к символу с определенным индексом, нужно использовать квадратные скобки:
Это выражение возвращает i-й символ строки. Например:
Если индекс выходит за пределы длины строки, вы увидите ошибку IndexError .
Давайте рассмотрим следующий пример.
Новичку в программировании может быть трудно запомнить, что индексация начинается с 0. Например, последний символ строки из 5 символов имеет индекс 4 . Но давайте посмотрим, что произойдет, если вы вдруг подумаете, что это 5:
Как можно заметить, результатом является ошибка, указывающая, что индекс находится вне допустимого диапазона.
Это потому, что с индексом 5 мы пытаемся получить доступ к 6-му элементу. Но поскольку данная строка имеет только 5 символов, доступ к 6-му с треском проваливается.
Таким образом, следует быть осторожным и не пытаться получить доступ к отсутствующему элементу строки.
Нарезка (slicing) строк
Из предыдущего раздела стало ясно как получить доступ к определенному символу строки.
Но иногда требуется получить доступ к определенному диапазону внутри строки.
Сделать это можно при помощи так называемой нарезки строк.
Самый простой вариант операции нарезки требует указания начального и конечного индекса:
Результатом является срез символов исходной строки. В него входят символы от начального до конечного индекса (при этом символ с конечным индексом в срез не входит).
Например, возьмем первые три буквы строки:
Полный синтаксис оператора среза включает в себя параметр шага и имеет следующий вид:
Параметр шага (step) указывает, через сколько символов следует перепрыгивать. По умолчанию он равен 1 , как вы наверно уже догадались.
Например, возьмем каждый второй символ из первых 8 символов строки:
Теперь вы должны понимать основные принципы нарезки строк в Python.
На практике срезы применяются очень разнообразно. Например, некоторые или даже все параметры среза можно опускать, а отсчет символов может идти в обратном направлении.
Но чтобы не раздувать материал, здесь мы не будем вдаваться в детали срезов.
Встраивание переменных внутрь строки
Довольно часто возникает необходимость добавить переменные внутрь строки Python.
Для этого можно использовать F-строки. F-строка означает просто «форматированная строка». Она позволяет нам аккуратно размещать код внутри строки.
Чтобы создать F-строку, нужно добавить символ f непосредственно перед строкой и обозначить фигурными скобками код, внедряемый в строку.
Как можно заметить, это аккуратным образом встраивает в строку имя, хранящееся в переменной name . Благодаря этому нам не нужно разбивать строку на три части, что было бы несколько неудобно.
Давайте рассмотрим еще один пример, чтобы убедиться, что внутри F-строки можно также запускать код:
От редакции Pythonist: на тему форматирования строк у нас есть отдельная статья — «Форматирование строк».
Изменение строк
В языке Python строки изменять нельзя.
Это связано с тем, что строки относятся к неизменяемым типам данных и представляет собой неизменяемые наборы символов.
От редакции Pythonist: на тему изменяемости объектов в Python рекомендуем почитать статью «Python 3: изменяемый, неизменяемый…».
Новичков это может несколько сбивать с толку.
Но изменять именно исходную строку приходится не часто, так что особых проблем неизменяемость строк не вызывает.
Если вам нужна измененная строка, можно просто создать новую строку из исходной с уже внесенными в нее изменениями. То есть новая строка является просто модифицированной копией исходной версии нашей строки.
На самом деле существует множество полезных встроенных методов для изменения строк. Эти методы помогают решить большинство повседневных задач.
И оставшаяся часть данной статьи будет посвящена именно этим методам.
Методы строк в языке Python
Во встроенном в Python модуле string есть множество удобных методов, которые можно использовать для работы со строками.
Они делают жизнь программиста гораздо проще.
Эти методы предназначены для решения самых общих задач, связанных как с изменением строк, так и с работой со строками в целом.
Например, можно заменить символ в строке при помощи метода replace() . Без этого метода это было бы не так просто сделать. Вам пришлось бы реализовать собственную логику для замены символа, так как непосредственное изменение строки невозможно.
И таких методов в Python довольно много. Если быть точными, то их 47. Не пытайтесь запомнить их все. Лучше почитайте про каждый из этих методов и попробуйте применить их.
Можно также добавить данную статью в закладки и возвращаться к ней потом по мере надобности.
Следующая таблица представляет собой шпаргалку с методами строк в Python. А ниже этой таблицы вы найдете более подробное описание каждого метода и пару полезных примеров по нему:
| Имя метода | Описание метода |
| capitalize | Преобразует первый символ строки в верхний регистр. |
| casefold | Преобразует строку в нижний регистр. Поддерживает больше вариантов, чем метод lower() . Используется при локализации либо глобализации строк. |
| center | Возвращает центрированную строку. |
| count | Возвращает количество вхождений символа или подстроки в строке. |
| encode | Производит кодировку строки. |
| endswith | Проверяет, заканчивается ли строка определенным символом либо определенной подстрокой. |
| expandtabs | Указывает размер табуляции для строки и возвращает его. |
| find | Ищет определенный символ или подстроку. Возвращает позицию, где он был впервые обнаружен. |
| format | Старый способ добавления переменных внутрь строки (выше мы рассмотрели современный метод F-строк). Форматирует строку, встраивая в нее значения и возвращая результат. |
| format_map | Форматирует определенные значения в строке. |
| index | Ищет символ или подстроку в строке. Возвращает индекс, по которому он был впервые обнаружен. |
| isalnum | Проверяет, все ли символы строки являются буквенно-цифровыми. |
| isalpha | Проверяет, все ли символы строки являются буквенными. |
| isascii | Проверяет, все ли символы строки являются символами ASCII. |
| isdecimal | Проверяет, все ли символы строки являются десятичными числами. |
| isdigit | Проверяет, все ли символы строки являются цифрами. |
| isidentifier | Проверяет, является ли строка идентификатором. |
| islower | Проверяет, все ли символы строки находятся в нижнем регистре. |
| isnumeric | Проверяет, все ли символы строки являются числами. |
| isprintable | Проверяет, все ли символы строки доступны для печати. |
| isspace | Проверяет, все ли символы строки являются пробелами. |
| istitle | Проверяет, соответствует ли строка правилам написания заголовков (каждое слово начинается с заглавной буквы). |
| isupper | Проверяет, все ли символы строки находятся в верхнем регистре. |
| join | Соединяет элементы итерируемого объекта (например, списка) в одну строку. |
| ljust | Возвращает выровненную по левому краю версию строки. |
| lower | Приведение всех символов строки к нижнему регистру. |
| lstrip | Удаляет пробелы слева от строки. |
| maketrans | Создает таблицу преобразования символов (для метода translate() ). |
| partition | Разбивает строку на три части. Искомая центральная часть указывается в качестве аргумента. |
| removeprefix | Удаляет префикс из начала строки и возвращает строку без него. |
| removesuffix | Удаляет суффикс из конца строки и возвращает строку без него. |
| replace | Возвращает строку, в которой определенный символ или подстрока заменены чем-то другим (другим символом или подстрокой). |
| rfind | Ищет в строке определенный символ или подстроку. Возвращает последний индекс, по которому он был найден. |
| rindex | Ищет в строке определенный символ или подстроку. Возвращает последний индекс, по которому он был найден (отличие данного метода от предыдущего только в том, что в случае неудачного поиска он возвращает ошибку). |
| rjust | Возвращает выровненную по правому краю версию строки. |
| rpartition | Разбивает строку на три части. Искомая центральная часть указывается в качестве аргумента. |
| rsplit | Разбивает строку по указанному разделителю и возвращает результат в виде списка. |
| rstrip | Удаляет пробелы справа от строки. |
| split | Разбивает строку по указанному разделителю и возвращает ее в виде списка элементов данной строки. |
| splitlines | Разбивает строку по разрывам (символам переноса строк) и возвращает список строк. |
| startswith | Проверяет, начинается ли строка с указанного символа или подстроки. |
| strip | Возвращает строку с удаленными пробелами с двух сторон. |
| swapcase | Все символы в верхнем регистре переводятся в нижний и наоборот. |
| title | Преобразует каждое слово строки так, чтобы оно начиналось с заглавной буквы. |
| translate | Возвращает переведенную строку. |
| upper | Переводит все символы строки в верхний регистр. |
| zfill | Заполняет строку символами 0 . |
Все строковые методы Python с примерами
В данном разделе дается более подробное описание каждого метода.
Помимо теории, для всех методов представлены полезные примеры.
capitalize
Чтобы сделать первую букву строки заглавной, удобно использовать данный метод.
casefold
Чтобы преобразовать все символы строки в нижний регистр, удобно использовать встроенный метод casefold() .
Этот метод создает новую строку, переводя каждый символ строки в нижний регистр.
Разница между методами casefold() и lower() заключается в том, что метод casefold() умеет преобразовывать специальные буквы других языков. Другими словами, использование casefold() имеет смысл, когда ваше приложение должно поддерживать глобализацию или локализацию на другой язык.
Например, давайте преобразуем предложение на немецком языке, чтобы избавиться от большого двойного знака (ß). Это невозможно при использовании метода lower() :
center
Метод center() используется, чтобы окружить (заполнить с двух сторон) строку заданными символами.
Этот метод имеет следующий синтаксис:
При вызове этого метода необходимо указать общее количество символов в строке и символ, которым строка будет окружена (заполнена с двух сторон).
Например, давайте добавим символы тире вокруг слова и сделаем всю строку длиной 20 символов:
count
Метод count() подсчитывает, сколько раз символ или подстрока встречается в строке.
Например, посчитаем количество букв l в предложении:
Или давайте посчитаем, сколько раз слово «Hello» встречается в этом же предложении:
encode
Чтобы изменить кодировку строки, используйте встроенный метод encode() .
Этот метод имеет следующий синтаксис:
Кодировкой по умолчанию является UTF-8. В случае неудачи кидается ошибка.
Например, давайте преобразуем строку в кодировку UTF-8:
Этот метод можно вызвать с двумя необязательными параметрами:
Существует 6 типов ошибок:
Вот несколько примеров ASCII-кодировки с разными типами ошибок:
endswith
Данный метод применяется для проверки, заканчивается ли строка или ее часть заданным символом или подстрокой.
expandtabs
При помощи метода expandtabs() можно указать размер табуляции. Этот метод полезен, если ваши строки содержат табы.
Метод find() находит индекс первого вхождения символа или подстроки в строку. Если совпадения нет, возвращается -1 .
Также можно указать диапазон, в котором выполняется поиск. Полный синтаксис для использования этого метода имеет следующий вид:
string.find(value, start, end)
Это означает, что строку world можно найти по индексу 6 в заданном предложении.
В качестве другого примера давайте найдем подстроку в заданном диапазоне:
format
Метод format() форматирует строку, встраивая в нее значения. Это несколько устаревший подход к форматированию строк в Python.
Метод format() имеет следующий синтаксис:
string.format(value1, value2, . , valuen)
Здесь value — это переменные, которые вставляются в строку. В дополнение к этому вам необходимо указать (при помощи фигурных скобок) места для этих переменных в строке.
Давайте посмотрим на следующий пример:
format_map
Метод format_map() используется, чтобы напрямую преобразовать словарь в строку.
Чтобы это работало, вам нужно указать (при помощи фигурных скобок) места в строке, куда будут помещены значения словаря.
index
Метод index() находит индекс первого вхождения символа или подстроки в строку. Если он не находит значение, то вызывается исключение. Этим он отличается от метода find() .
Также можно указать диапазон, в котором будет производится поиск.
Синтаксис данного метода имеет следующий вид:
string.index(value, start, end)
Это говорит о том, что подстроку world можно найти по индексу 6 в данной строке.
В качестве другого примера давайте найдем подстроку в заданном диапазоне:
Разница между методами index() и find() заключается в том, что index() выдает ошибку, если не находит значения. Метод find() возвращает -1 .
isalnum
Чтобы проверить, являются ли все символы строки буквенно-цифровыми, используется метод isalnum() .
isalpha
Чтобы проверить, все ли символы строки являются буквами, используется метод isalpha() .
isascii
Чтобы проверить, все ли символы строки являются ASCII символами, используется метод isascii() .
isdecimal
Чтобы проверить, являются ли все символы строки числами в десятичной системе исчисления, используется метод isdecimal() .
isdigit
Чтобы проверить, все ли символы строки являются числами, используется метод isdigit() .
isidentifier
Чтобы проверить, все ли символы строки являются идентификаторами, используется метод isidentifier() .
islower
Чтобы проверить, находятся ли все символы строки в нижнем регистре, используется встроенный метод islower() .
Этот метод проверяет, все ли символы строки находятся в нижнем регистре. Если это так, он возвращает True . В противном случае False .
isnumeric
Чтобы проверить, все ли символы строки являются числами, используется метод isnumeric() .
isprintable
Чтобы проверить, все ли символы строки доступны для печати, используется метод isprintable() .
isspace
Чтобы проверить, являются ли все символы строки пробелами, используется метод isspace() .
istitle
Чтобы проверить, все ли первые символы каждого слова в строке начинаются с заглавной буквы, используется метод istitle() .
isupper
Чтобы проверить, находятся ли все символы строки в верхнем регистре, используется встроенный метод isupper() :
Этот метод проверяет, все ли символы строки в верхнем регистре. Если это так, он возвращает True . В противном случае False .
Чтобы объединить группу элементов (например, списка) в одну строку, используется метод join() .
ljust
Чтобы добавить определенные символы, например пробелы, справа от строки, используется метод ljust() .
Например, добавим справа от строки символ тире:
lower
Чтобы привести строку Python к нижнему регистру, используется встроенный метод lower() .
Этот метод создает новую строку, переводя каждый символ первоначальной строки в нижний регистр.
lstrip
Чтобы удалить начальные символы из строки, используется метод lstrip() .
По умолчанию этот метод удаляет все пробелы в начале строки.
В качестве другого примера давайте удалим все дефисы в начале следующей строки:
maketrans
Чтобы создать таблицу сопоставления строк, используется метод maketrans() . Эта таблица применяется вместе с методом translate() .
Синтаксис имеет следующий вид:
Например, заменим в предложении символы о на х :
partition
Чтобы разделить строку на три части, используется метод partition() . Он разбивает строку вокруг определенного символа или подстроки. Результат возвращается в виде кортежа.
Например, можно с его помощью разделить предложение вокруг заданного слова:
removeprefix
Для удаления начала строки используется метод removeprefix() . Надо заметить, что это относительно новый метод, он работает только начиная с версии Python 3.9 и выше.
Например, давайте удалим слово This из данного предложения:
removesuffix
Для удаления конца строки используется метод removesuffix(). Это также новый метод, он работает только с версией Python 3.9 и выше.
Например, давайте удалим из данного предложения последнее слово test:
replace
Чтобы заменить символ или подстроку внутри строки на что-то другое, используется метод replace() :
Он имеет следующий синтаксис:
string.replace(old, new, count)
rfind
Для нахождения индекса последнего вхождения символа или подстроки в строку используется метод rfind() . При отсутствии совпадений возвращается значение -1 .
rindex
Для нахождения индекса последнего вхождения символа или подстроки в строку также можно использовать метод rindex() . Но если вхождений найдено не будет, данный метод вызовет исключение. В этом его отличие от метода rfind() , который возвращает -1.
string.rindex(val, start, end)
rjust
Метод rjust() используется для добавления слева от строки определенных символов, например пробелов.
У него следующий синтаксис:
Например, добавим символы тире в начало строки:
rpartition
Данный метод разделяет строку на три части относительно последнего вхождения искомого символа или подстроки. Результат возвращается в виде кортежа.
rsplit
Для разбиения строки по определенному разделителю начиная с правой стороны используется метод rsplit() . Результат возвращается в виде списка.
Например, давайте разделим справа строку, разделенную запятыми. Но при этом сделаем только одно разбиение:
Обратите внимание, что данный массив состоит только из двух строк.
rstrip
При помощи метода rstrip() можно удалять определенные символы, начиная с конца строки.
Если не указывать аргументов, данный метод будет пытаться удалять пробелы справа от строки.
Например, давайте удалим символ тире из строки:
split
При помощи метода split() строку можно превратить в список строк, разбив ее на части. Это один из наиболее широко используемых строковых методов Python.
По умолчанию данный метод разбивает строку на основе пробелов.
В качестве другого примера давайте разобьем список, разделенный запятыми, ровно два раза, по двум первым запятым:
Обратите внимание, что в данном списке только 3 элемента.
splitlines
Чтобы разбить текст, считанный в виде строки, по символам разрыва строки, используется метод splitlines() .
Вы также можете оставить символы разрыва строк в конце каждой строки. Для этого нужно передать параметр True в качестве аргумента данного метода:
startswith
Чтобы проверить, начинается ли строка с определенного значения, используется метод startwith() .
string.startswith(val, start, end)
Теперь перейдем к другому примеру. На этот раз давайте посмотрим, есть ли в строке, начиная с 6-го индекса, подстрока wor :
strip
Чтобы удалить определенные символы или подстроку из строки, используется метод strip() . По умолчанию этот метод удаляет пробелы. Также можно указать аргумент, который будет определять, какие именно символы нужно удалить.
Например, давайте удалим все символы тире из строки:
swapcase
Чтобы сделать строчные буквы заглавными, а заглавные строчными, используется метод swapcase() .
Этот метод создает новую строку, заменяя все заглавные буквы на строчные и наоборот.
title
Чтобы сделать первую букву каждого слова в строке заглавной, используется метод title() .
Этот метод создает новую строку, делая первую букву каждого слова заглавной.
translate
Чтобы заменить определенные символы строки на другие символы, используется метод translate() .
Но прежде чем это делать, нужно создать таблицу сопоставления при помощи метода maketrans() .
Например, давайте заменим буквы о на х :
upper
Чтобы преобразовать строку Python в верхний регистр, используется встроенный метод upper() .
Этот метод создает новую строку, переводя каждый символ исходной строки в верхний регистр.
zfill
Данный метод добавляет нули перед исходной строкой.
В качестве аргумента нужно передать желаемую длину строки и, метод добавит нужное количество нулей перед строкой.
Обратите внимание, что общая длина этой строки теперь равна 10.
Источник статьи: http://pythonist.ru/stroki-v-python-polnoe-rukovodstvo/
Строки в Python от А до Я

Python – популярный язык разработки, которому обучаются многие программисты. Он является скриптовым, общего назначения. Обладает широким применением в различных сферах – от веб-страниц до формирования сложных клиент-серверных систем. Является универсальным средством разработки.
Для того, чтобы создавать приложения на Python, разработчику потребуется выучить его основы и инструменты, а также библиотеки и фреймворки. А еще – разобраться с базовой терминологией в программировании, которая поможет быстрее освоить материал.
Данная статья расскажет о строках. Они широко используются в разработке самых разных приложений на Python. Соответствующие компоненты можно применять относительно всего, что может быть представлено в текстовой форме.
Особенности Python
Перед тем как изучать the strings в Питоне, необходимо выяснить, какие сильные и слабые стороны есть у данного языка программирования. Он используется в:
Для игрового программного обеспечения Python тоже применяется, но обычно в качестве дополнения. На нем можно создать элементарные приложения, а вот для более сложных продуктов придется использовать иные ЯП.
Недостатки у The Python тоже имеются:
Данный язык программирования отлично подходит новичкам, а также тем, кто пока не планирует особо крупные проекты. Нередко The Python изучается в качестве дополнения. С его помощью удается сделать большинство масштабных разработок более функциональными и понятными.
Основная терминология в программировании
Для того, чтобы работать со строками и иными компонентами при создании кода приложения на Питоне, нужно освоить базовые термины. Без них не получится разобраться ни с одним исходным файлом программы:
Также стоит запомнить понятие синтаксиса. Это установленные языком правила о том, как грамотно передавать операторы.
Данная информация поможет быстрее освоить базовые навыки программирования, а также не путаться в имеющемся коде и читать его. Предложенные определения относятся к объектно-ориентированной разработке.
Строки – базовые навыки работы
The string – это строка. Так называется тип данных, используемый для представления текста. The string относится к базовому типу. Последовательности символов в упорядоченном виде, которые применяются при хранении и представлении текстовой информации.
Для того, чтобы создать the string, нужно использовать одинарные или двойные кавычки. Форма представления данного компонента:
При выборе того или иного варианта необходимо действовать внимательно и последовательно. Кавычки в the strings можно использовать любые, но лучше использовать по проекту единый стиль исполнения.
Стоит обратить внимание на то, что строки в апострофах и в кавычках – это разные составляющие кода. Это позволяет вставлять в литералы the strings символы кавычек/апострофов без экранирования.
Если перед открывающейся кавычкой стоит r в любом регистре, то экранирование будет отключено. Можно в процессе разработки в the strings использовать тройные кавычки. Они применяются для многострочных блоков текста. Внутри такой the string поддерживается присутствие кавычек и апострофов. Главное, чтобы не было трех кавычек подряд:
Далее будут рассмотрены ключевые моменты, связанные с работой с the strings in Python. Предложенная информация пригодится не только опытным разработчикам, но и новичкам.
Операторы
The strings – элемент кода будущего приложения, с которым можно выполнять различные действия. Для этого применяются те или иные операторы. Аккуратно требуется применять:
Особо полезным станет проверка на наличие содержания в the string подстроки или символа. За соответствующую операцию отвечает operator in.
Сложение
Теперь можно изучить эти три оператора. Они применяются на практике чаще всего. При помощи оператора сложения (+) допускается объединение двух или несколько strings:
При обработке соответствующего кода в качестве результата на экран будет выведена the string со словом somewhere.
Умножение
The string поддерживает оператор умножения. Он используется для аналогичной математической операции, но с текстовыми данными. Ниже приведен наглядный пример кода:
При его обработке на консоли появится надпись hellohellohello. Связано это с тем, что заданная переменная word должна повторяться трижды.
Оператор in
In the string можно задействовать оператор in. Это своеобразная проверка нахождения подстроки или символа в заданной последовательности. Применяется для того, чтобы определить, есть ли конкретное слово или символ in the string.
Рекомендуется запомнить следующие правила:
Соответствующая концепция может применяться в большинстве сложных задач:
Выше – пример того, как будут условно выглядеть описанные ранее правила. А вот вариант с поиском конкретного символьного значения:
Тут программа ищет символ «e» в заданном слове. При его обнаружении выводит на экран True, в противном случае – False.
Индексация
String in the Python – это некий набор символов. Каждый элемент в строке обладает так называемым индексом – порядковым номером. С его помощью можно получить доступ к любому символу в string.
Об индексации в строках Питона необходимо запомнить следующее:
Вот наглядный пример, который вернет i-ый символ заданной string:
А вот еще один пример. Он поможет лучше освоить индексы в the string:
Ошибка появляется из-за того, что разработчик пытается получить доступ к элементу с несуществующим индексом. С index = 5 происходит обращение к шестому компоненты в заданной строке.
Нарезка
В некоторых задачах приходится производить так называемую нарезку. Она позволяет получить доступ к определенному внутри string диапазону. Самый простой подход требует указания начальных и конечных индексов. Форма записи:
Результатом послужит срез символов заданной исходной строки. Туда будут включены элементы от начального до конечного индекса. «Последний» не включен в полученный срез.
Полный синтаксис соответствующего оператор подразумевает дополнительный параметр – шаг. Форма представления:
Шаг указывает, через сколько символов необходимо «перепрыгивать». При пропуске (по умолчанию) этот параметр равен единице.
Выше – пример, предусматривающий вывод каждого второго символа из первых 8 в the string.
Встройка переменных
Переменная – это элементарное место хранения информации с заданным именем. Довольно часто в задачах Python требуется вписывать их в strings. Для этого используются F-строки (форматированные строки). С их помощью получается гармонично вписать программный код в пределах the string.
Для создания F-строки требуется добавить f перед соответствующим компонентом кода. Далее – в квадратных скобках написать желаемый фрагмент приложения:
Здесь происходит встраивание в строку имени. Оно хранится в переменной под названием name. Разбирать строку на несколько частей теперь не придется.
Выше – наглядный пример, доказывающий возможность использования блоков кода внутри F-строк.
Изменение строк
Python strings нельзя изменять. Связано это с тем, что строка в данном языке программирования выступает в качестве неизменного типа данных. Выражается константным набором символов.
Для того, чтобы вывести на экран «измененную» строку, достаточно создать новую string из исходной с уже внесенными изменениями. Новый элемент выступит модифицированной копией первоначального компонента.
В Python много встроенных методов, позволяющих работать со строками. Они широко используются для решения большинства задач в разработке.
Методы для работы со строками
Встроенный модуль string обладает огромным количеством methods, которые используются для оперирования строками. Применяются для более быстрой разработки.
Пример – метод replace(). Он позволит заменить символ in the string на другой. Без данного метода разработчику пришлось бы реализовывать собственную логику внесения изменений. Связано это с невозможностью корректировки strings в Питоне «по умолчанию».
Всего в изучаемом языке программирования 47 методов работы со строками. Далее предстоит рассмотреть их более подробно.
Склеивание и разделение
Один из способов «склеивания» строк – это использование оператора «+». В Python для этого существует отдельных метод. Он носит название join(). Перед ним необходимо указать разделитель the string, а в скобках – необходимый массив информации:
Для разделения string используется обратный метод – split(). В нем:
Пример выше объясняет принцип работы данного приема. Можно разделить строки в Python при помощи так называемого среза. Он имеет вид:
Позволяет получить строку от символа x до y. Оба параметра указывать не обязательно. Если не написать значение y, произойдет срез до конца заданной the string.
Еще один способ «срезать» каждый n-символ в строке – это использование двойного двоеточия. Выше можно увидеть фрагмент кода, объясняющий соответствующий алгоритм.
Поиск
Для поиска набора символов в начале или конце заданного текстового строкового массива можно воспользоваться несколькими методами:
Если необходимо обнаружить символы в произвольном месте строки, потребуется задействовать метод find().
В приведенном примере происходит вывод -1 из-за того, что приложение не обнаружило искомое значение в заданной строке.
Замена
Следующий удобный метод отвечает за замену. Ниже – образец кода, работающий с ним:
Для того, чтобы заменить набор символов на другой в пределах the string, потребуется задействовать метод replace().
Каждый элемент отдельно и длина
Strings в Питоне иногда требуют получения и обработки каждого имеющегося символа отдельно друг от друга. Для этого рекомендуется воспользоваться циклом for.
А для того, чтобы получить длину the string, требуется метод len().
Строка в число и регистр
Если есть строка, включающая в себя цифры, можно преобразовать ее в число. Для этого необходимо, чтобы другие типы текста отсутствовали. Используется для операции функция приведения int().

Чтобы заменить регистр всех букв в the string и сделать их заглавными, необходимо применить метод upper(). Для строчных элементов используется lower(). Чтобы сделать букву в строке заглавной, применяется метод capitalize().
Удаление пробелов
Иногда в строке в процессе написания кода появляются лишние пробелы. Они мешают отображению информации при исполнении приложения. Для устранения данной проблемы используются методы:
Это – базовые методы, используемые на практике чаще остальных. Оперируя доступными вариантами, можно создавать весьма сложные приложения в Питоне.
Таблица методов
The strings имеют 47 методов для работы с рассматриваемым компонентом. Некоторые из них используются весьма редко, они применяются преимущественно опытными разработчиками:
| Название | Описание |
| Casefold | Отвечает за преобразование the string в нижний регистр. Имеет больше вариантом, чем lower. Применяется при локализации/глобализации. |
| Count | Отвечает за возврат количества вхождений символа или подстроки |
| Center | Возвращение центрированной the string |
| Endwith | Проверка на то, заканчивается ли string определенным символом/подстрокой |
| Encode | Кодировка the string |
| Find | Отвечает за поиск конкретного символа или подстроки. Возвращает позицию, где элемент был впервые обнаружен |
| Expandtabs | Указывает табуляцию и осуществляет ее возврат |
| Format | Добавляет переменные внутрь имеющейся последовательности. Форматирует the string путем встраивания в нее значений. Далее возвращает результат. |
| Format_map | Форматирование определенных значений |
| isalnum | Метод, который проверяет, все ли символы в заданной последовательности относятся к буквам и цифрам |
| Capitalize | Преобразование первого символа в верхний регистр |
| Index | Поиск элемента в the string. Возвращает индекс, по которому компонент был впервые обнаружен. |
| Isascii | Проверка на принадлежность всех компонентов к таблице ASCII |
| Isalpha | Все ли элементы заданной последовательности относятся к буквенным |
| Isdigit | Проверка на принадлежность всех составляющих в цифрам |
| Isdecimal | Проверка на отношение к десятичным числам |
| Join | Соединение нескольких объектов в одну the string |
| Lower | Печать всего массива в нижнем регистре |
| Ljust | Выравнивание по левому краю |
| Ipupper | Проверка на верхний регистр всех элементов в «массиве» |
| Istitle | Соответствие the string действующим правилам написания заголовка (каждое слово – с заглавной буквы) |
| Isprintable | Проверка символов на доступность для печати |
| Isspace | Используется, чтобы удостовериться в том, что все элементы последовательности – пробелы |
| Isnumeric | Все ли символы строки – это цифры |
| Istrip | Удаление пробелов слева |
| Maketrans | Создание таблицы преобразования элементов (для метода translate()) |
| Removesuffix | Удаление суффикса из конца «массива» |
| Removeprefix | Избавление от префикса |
| Replace | Возвращает the string, в которой конкретный компонент или подстрока заменены чем-то иным |
| Rfind | Возврат последнего индекса по заданному искомому компоненту |
| Rindex | Возвращает последний индекс, по которому в the string был обнаружен элемент. При неудаче выводит на дисплей устройства сообщение об ошибке. |
| Rjust | Выравнивание по правому краю |
| Rsplit | Разбиение по указанному разделителю |
| Rpartition | Деление на три части. Искомая центральная область выступает аргументом метода. |
| Rstrip | Удаление пробелов справа |
| Split | Разделение по заданному разделителю. Вернет значение в качестве списка компонентов in the string. |
| Statwith | Проверяет, начинается ли «массив» с заданного компонента |
| Splitlines | Разбивает the string по символам переноса. Результатом становится возврат списка строк. |
| Title | Преобразование каждого слова. После применения метода все элементы в «массиве» будут начинаться с заглавных букв. |
| Upper | Перевод имеющихся в строчке символов (всех) в верхний регистр |
| Swapcase | Перевод всех символов в нижний регистр, а также наоборот |
| Translate | Перевод |
| Zfill | Заполнение строчки нулями. |
Данная таблица поможет понять, что можно выполнить со строками в Питоне без дополнительной разработки собственной логики и сложных алгоритмов.
Как быстро освоить направление
Python – язык программирования с достаточно простым синтаксисом. Его многие стараются выучить самостоятельно. В этом помогают различная специализированная литература, а также видео-уроки. Только самообразование может затянуться. Оно не имеет документального подтверждения приобретенных навыков и знаний, а теме «strings in the Python» посвящено множество статей. Там не всегда материал подается полно и понятно.
Чтобы Питон и любой его компонент были понятны, рекомендуется закончить дистанционные компьютерные курсы. На них:
Пользователи смогут выбрать одно или несколько направлений в зависимости от имеющегося багажа знаний. Завершается каждый дистанционный курс вручением сертификата для документального подтверждения приобретенных навыков во время учебы.
Источник статьи: http://otus.ru/journal/stroki-v-python-ot-a-do-ya/
Строки (String)
До сих пор мы обсуждали числа как стандартные типы данных в Python. В этом разделе учебника мы рассмотрим самый популярный тип данных в Python – строку.
Строка в Python – это набор символов, окруженных одинарными, двойными или тройными кавычками. Компьютер не понимает символы; внутри он хранит управляемый символ как комбинацию 0 и 1 .
Каждый символ кодируется в ASCII или Unicode. Поэтому можно сказать, что строки Python также называют коллекцией символов Unicode.
В Python строки можно создавать, заключая символ или последовательность символов в кавычки. Python позволяет нам использовать одинарные, двойные или тройные кавычки для создания строки.
Рассмотрим следующий пример на языке Python для создания строки.
Если мы проверим тип переменной str с помощью сценария Python print(type(str)) , то будет выведено:
В Python строки рассматриваются как последовательность символов, что означает, что Python не поддерживает символьный тип данных; вместо этого один символ, записанный как p , рассматривается как строка длины 1 .
Создание строки в Python
Мы можем создать строку, заключив символы в одинарные или двойные кавычки. Python также предоставляет тройные кавычки для представления строки, но они обычно используются для многострочных строк или документов.
Индексация и разбиение строк в Python
Как и в других языках, индексация строк в Python начинается с 0 . Например, строка “HELLO” индексируется так, как показано на рисунке ниже.

Рассмотрим следующий пример:
В Python мы можем использовать оператор : (двоеточие) для доступа к подстроке из заданной строки. Рассмотрим следующий пример.

Здесь мы должны заметить, что верхний диапазон, заданный в операторе slice , всегда является эксклюзивным, т.е. если задано str = ‘HELLO’ , то str[1:3] всегда будет включать str[1] = ‘E’ , str[2] = ‘L’ и ничего больше.
Рассмотрим следующий пример:
Мы можем сделать отрицательную нарезку в строке; она начинается с самого правого символа, который обозначается как -1 . Второй крайний правый индекс обозначает -2 , и так далее. Рассмотрим следующее изображение.

Рассмотрим следующий пример
Переназначение строк
Обновить содержимое строки так же просто, как присвоить его новой строке. Объект string не поддерживает присваивание элементов, т.е. строка может быть заменена только новой строкой, поскольку ее содержимое не может быть частично заменено. В Python строки неизменяемы.
Рассмотрим следующий пример.
Однако в примере 1 строка str может быть полностью присвоена новому содержимому, как указано в следующем примере.
Удаление строки в Python
Как мы знаем, строки неизменяемы. Мы не можем удалить или убрать символы из строки. Но мы можем удалить всю строку, используя ключевое слово del .
Пробуем удалить часть строки:
Теперь мы пробуем удалить всю строку:
Строковые операторы в Python
| Оператор | Описание |
|---|---|
| + | Ооператор конкатенации, используемый для соединения строк, заданных по обе стороны от оператора. |
| * | Оператор повторения. Он объединяет несколько копий одной и той же строки. |
| [] | Оператор среза. Он используется для доступа к подстрокам определенной строки. |
| [:] | Оператор среза диапазона. Он используется для доступа к символам из указанного диапазона. |
| in | Оператор членства. Он возвращает, присутствует ли определенная подстрока в указанной строке. |
| not in | Оператором членства и выполняет прямо противоположное действие по отношению к in . Он возвращает true , если определенная подстрока отсутствует в указанной строке. |
| r/R | Используется для указания необработанной строки. Необработанные строки используются в тех случаях, когда необходимо вывести фактическое значение управляющих символов, таких как C://python . Чтобы определить любую строку как необработанную, за строкой следует символ r или R . |
| % | Он используется для форматирования строк. Он использует спецификаторы формата, применяемые в программировании на языке C , такие как %d или %f , для отображения их значений в python. |
Рассмотрим следующий пример, чтобы понять использование операторов Python.
Форматирование строк в Python
Экранирование последовательности
Допустим, нам нужно записать текст в виде – They said, “Hello what’s going on?”- данное утверждение может быть записано в одинарных или двойных кавычках, но оно вызовет SyntaxError , так как содержит как одинарные, так и двойные кавычки.
Рассмотрим следующий пример, чтобы понять реальное использование операторов Python.
Мы можем использовать тройные кавычки для решения этой задачи, но Python предоставляет возможность экранировать нашу последовательнсть символов.
Символ обратной косой черты ( / ) обозначает escape последовательность. За обратной косой чертой может следовать специальный символ, который интерпретируется по-разному. Одинарные кавычки внутри строки должны быть экранированы. Мы можем применить то же самое, что и в случае с двойными кавычками.
Ниже приведен список управляющих последовательностей для экранирования:
| Escape последовательность | Описание |
|---|---|
| \newline | Игнорирует новую строку. |
| \\ | Обратный слэш |
| \’ | Одинарные кавычки |
| \\” | Двойные кавычки |
| \a | ASCII гудок |
| \b | ASCII Backspace(BS) |
| \f | ASCII Formfeed (смещение к началу след. страницы) |
| \n | ASCII Linefeed (перевод на след. строку) |
| \r | ASCII Carriege Return(CR) (перемещение курсора к левому краю поля) |
| \t | ASCII горизонтальная табуляция |
| \v | ASCII вертикальная табуляция |
| \ooo | Символ с восьмеричным значением |
| \xHH | Символ с шестнадцатеричным значением. |
Вот простой пример использования escape-последовательности.
Мы можем игнорировать управляющую последовательность из заданной строки, используя необработанную строку. Для этого перед строкой нужно написать r или R . Рассмотрим следующий пример.
Метод format() в python
Метод format() является наиболее гибким и полезным методом форматирования строк. Фигурные скобки <> используются в качестве заполнителя строки и заменяются аргументом метода format() . Рассмотрим приведенный пример:
Форматирование строк в Python с помощью оператора %
Python позволяет нам использовать спецификаторы формата, используемые в операторе printf языка Си . Спецификаторы формата в Python обрабатываются так же, как и в C. Однако Python предоставляет дополнительный оператор % , который используется в качестве интерфейса между спецификаторами формата и их значениями. Другими словами, можно сказать, что он связывает спецификаторы формата со значениями.
Рассмотрим следующий пример.
Строковые функции в Python
Python предоставляет различные встроенные функции, которые используются для работы со строками.
Источник статьи: http://forproger.ru/tutorial-article/stroki-v-python
Основы работы со строками в Python
До сих пор мы обсуждали числа как стандартные типы данных в Python. В этом разделе руководства мы обсудим самый популярный тип данных, то есть строку и методы работы со строками в Python.
Что такое строка в Python?
Строка Python – это набор символов, заключенных в одинарные, двойные или тройные кавычки. Компьютер не понимает персонажей; внутри он хранит манипулируемый символ как комбинацию нулей и единиц.
Каждый символ кодируется символом ASCII или Unicode. Таким образом, мы можем сказать, что строки Python также называются набором символов Unicode.
В Python строки можно создавать, заключая символ или последовательность символов в кавычки. Python позволяет нам использовать одинарные кавычки, двойные кавычки или тройные кавычки для создания строки.
Рассмотрим следующий пример на Python для создания строки.
Проверим тип переменной str с помощью скрипта
В Python строки рассматриваются как последовательность символов, что означает, что Python не поддерживает символьный тип данных; вместо этого одиночный символ, записанный как ‘p’, рассматривается как строка длины 1.
Создание строки в Python
Мы можем создать строку, заключив символы в одинарные или двойные кавычки. Python также предоставляет тройные кавычки для представления строки, но обычно используется для многострочных строк или строк документации.
Индексирование и разбивка строк
Как и в других языках, индексирование строк Python начинается с 0. Например, строка «HELLO» индексируется, как показано на рисунке ниже.

Рассмотрим следующий пример:
Как показано в Python, оператор slice [] используется для доступа к отдельным символам строки. Однако мы можем использовать оператор:(двоеточие) в Python для доступа к подстроке из данной строки. Рассмотрим следующий пример.

Здесь мы должны заметить, что верхний диапазон, указанный в операторе среза, всегда является исключающим, т.е. если задано str = ‘HELLO’, тогда str [1: 3] всегда будет включать str [1] = ‘E’, str [2 ] = ‘L’ и ничего больше.
Рассмотрим следующий пример:
Мы можем сделать отрицательную нарезку строки; она начинается с крайнего правого символа, который обозначается как -1. Второй крайний правый индекс указывает -2 и так далее. Рассмотрим следующее изображение.

Рассмотрим следующий пример:
Переназначение строк
Обновить содержимое строк так же просто, как присвоить его новой строке. Строковый объект не поддерживает присвоение элемента, т. е. строка может быть заменена только новой строкой, поскольку ее содержимое не может быть частично заменено. Строки неизменяемы в Python.
Рассмотрим следующий пример.
Однако в примере 1 строку str можно полностью присвоить новому содержимому, это указано в следующем примере.
Удаление строки
Как мы знаем, строки неизменяемы. Мы не можем удалить символы из строки. Но мы можем удалить всю строку с помощью ключевого слова del.
Теперь мы удаляем всю строку.
Строковые операторы
| Оператор | Описание |
|---|---|
| + | Он известен как оператор конкатенации, используемый для соединения строк по обе стороны от оператора. |
| * | Известен как оператор повторения. Он объединяет несколько копий одной и той же строки. |
| [] | оператор среза. Он используется для доступа к подстрокам определенной строки. |
| [:] | оператор среза диапазона, используется для доступа к символам из указанного диапазона. |
| in | Оператор членства. Он возвращается, если в указанной строке присутствует определенная подстрока. |
| not in | Также является оператором членства и выполняет функцию, обратную in. Он возвращает истину, если в указанной строке отсутствует конкретная подстрока. |
| r / R | Используется для указания необработанной строки. Необработанные строки применяются в тех случаях, когда нам нужно вывести фактическое значение escape-символов, таких как «C: // python». Чтобы определить любую строку как необработанную, за символом r или R следует строка. |
| % | Необходим для форматирования строк. Применяет спецификаторы формата, используемые в программировании на C, такие как %d или %f, для сопоставления их значений в python. Мы еще обсудим, как выполняется форматирование в Python. |
Рассмотрим следующий пример, чтобы понять реальное использование операторов Python.
Форматирование строки Python
Управляющая последовательность
Предположим, нам нужно написать текст – They said, “Hello what’s going on?” – данный оператор может быть записан в одинарные или двойные кавычки, но он вызовет ошибку SyntaxError, поскольку он содержит как одинарные, так и двойные кавычки.
Рассмотрим следующий пример, чтобы понять реальное использование операторов Python.
Мы можем использовать тройные кавычки для решения этой проблемы, но Python предоставляет escape-последовательность.
Символ обратной косой черты(/) обозначает escape-последовательность. За обратной косой чертой может следовать специальный символ, который интерпретируется по-разному. Одиночные кавычки внутри строки должны быть экранированы. Мы можем применить то же самое, что и в двойных кавычках.
Список escape-последовательностей приведен ниже:
| Номер | Последовательность | Описание | Пример |
|---|---|---|---|
| 1. | \newline | Игнорирует новую строку |